 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
近期,国内大模型公司在长上下文窗口技术上再次取得突破,无损上下文长度提升至200万字数量级。我们认为法律场景是长文本领域的重要应用场景。当前国内外已有厂商发布了面向法院、企业法务等客户的法律AI产品,我们认为未来AI法务助手有望成为关键的发展方向。建议持续关注法律AI相关的研究进展。
摘要
法律行业是通用大模型重要的落地场景,法律垂类大模型在训练数据、监督算法方面实现进一步升级。通用大模型可以处理一定的法律概念和术语,赋能文件起草、辅助判决、辅助庭审、法律咨询等工作。考虑到法律行业对专业知识储备和法律文件规范性、准确性等要求高,我们认为训练出专门针对法律行业的垂类大模型仍有必要,其在大模型的基础上,解决通用大模型在法律领域存在专业知识储备不足和生成结果失真等问题,以更精准地理解概念和分析问题,满足法律从业人员的工作需求。
海外AI+法律应用加速,2B应用为主,目标客户多为律师、公司法务团队,收费模式上许可证、SaaS模式并存。2023年以来海外法律科技公司融资活跃,相关AI应用也在快速落地:海外AI+法律产品服务对象主要瞄准律师事务所、公司法务团队,多数AI法律产品具备文件总结、合同起草等功能;头部厂商Casetext、Harvey、LexisNexis等开发虚拟法务助手,为法律工作者提供多维、快速的AI法律服务能力,我们认为虚拟法务助手有望成为未来发展方向。
国内公司利用AI、大模型加速法律信息化建设。国内与海外在法律市场规模、律师执业情况、法院制度方面存在差异,国内AI+法律应用落地场景包括:为律协建立法律AI平台应用,支持司法部门、企业法务部门效率提升;应用功能主要包含知识检索、阅卷、庭审、文书等。法律信息化公司积极拥抱AI:华宇软件与百度、腾讯等国内顶尖大模型厂商达成生态合作协议,2023年7月10日正式发布法律大模型产品“万象”;通达海打造智慧法院全流程解决方案,积极构建AI能力平台;金桥信息升级多元解纷平台;幂律智能联合智谱AI推出聚焦合同领域的垂类大模型PowerLawGLM。
风险
国内法律垂类大模型落地应用不及预期;行业竞争加剧。
AI+法律:法律行业是垂类大模型落地的重要场景
1977年麦卡蒂发布法律行业的首个应用软件系统,标志着法律科技1.0时代到来[1]。自此,随着计算机技术发展、法律行业信息化程度提升,法律科技逐步向业务流程自动化、决策智能化方向升级。2022年末,ChatGPT的发布标志着人工智能进入大模型时代,基于其通用性特征,各行业可以建立垂类大模型。2024年3月,Kimi智能助手在长上下文窗口技术上再次取得突破。
我们认为法律是长文本处理领域的重要应用场景,当前通用大模型已经能够适配多种法律场景,但考虑到法律行业对专业知识储备和法律文件规范性、准确性等要求较高,我们认为训练出专门针对法律行业的垂类大模型仍有必要,在训练阶段使用专业法律指令数据集微调通用大模型,并在推理阶段提升指示词质量,其可以更好地理解、生成法律语言,帮助解决法律研究、案例分析、合同审查等任务,从而提高法律行业的工作效率。
法律科技:赋能法律服务,市场空间广阔
法律科技行业发展经历三个阶段,人工智能算法、数据分析决策成为目前关注焦点。根据哈佛大学[2],法律科技行业发展分为三个阶段:1.0阶段,法律软件辅助法律工作者完成法律研究、文档制作等工作;2.0阶段,法律工作逐步自动化;3.0阶段,先进的通信和计算机技术使得法律决策自动化成为可能,AI算法、大数据等技术在法律创新的作用成为当下关注的重点。
图表1:法律科技行业发展阶段
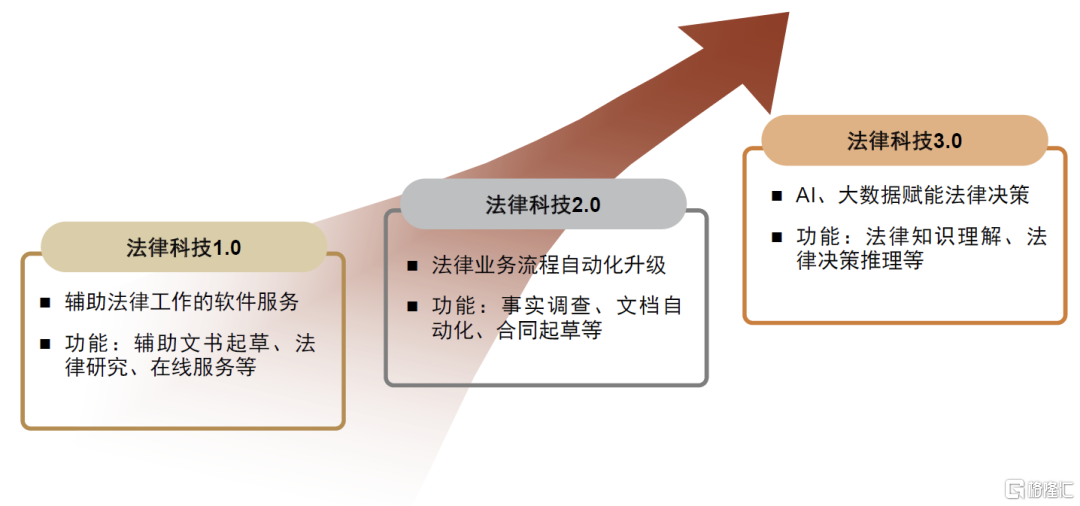
资料来源:Legal Technology 3.0,中金公司研究部
法律服务公司依托相关科技公司的软件产品和硬件设施,为多类型客户提供专业服务。法律服务行业上游的IT供应商包括软件公司和配套设施厂商,软件公司主要提供依托于大数据、区块链、人工智能等技术的法律科技产品,硬件厂商提供材料供应、云服务器、网络运维等基础设施建设。法律服务公司包括律所、法院等,主要为下游个人用户和各行业的企业客户提供文书处理、代理诉讼、法律咨询、案情分析、案件审理等服务。
► ToG服务:客户可以分为司法环节(法院、检察院)和执法环节(公安、纪检监察、政法委、司法行政等),提供软件产品和解决方案服务,包括法院信息化推进、业务智能辅助等。这一领域是国内法律服务主要的对象,根据IDC数据,2022年法检行业IT解决方案市场空间21.2亿人民币,其中华宇软件、科大讯飞、通达海份额前三。
► ToL(Lawyer)服务:为律师提供工作相关的支持性服务,支持诉讼和非诉多种业务,包括提供案例数据库、合同审查软件、客户管理平台等。这一领域是国外法律科技的聚焦领域,国内渗透率较低。目前国内重要产品如北大法宝,向使用者提供法律法规数据库和智能法律检索系统。
► ToB服务:主要为企业法务部提供相关服务,包括合同管理、合规检查以及企业法务平台等等。该领域公司如法大大提供电子合同与电子签云服务平台,是企业数字化转型的重要组成部分。
► ToC服务:提供一些法律咨询产品。公众可以使用这些产品解决简单的常见法律问题,得到相对专业的法律意见,从而降低法律部门的压力,提高解决效率。目前C端客户付费意愿低,往往以法律服务部门和律所购买相关产品,向公众提供服务为主,如以12348中国法律服务网为平台,提供智能法律咨询产品等。
图表2:法律服务行业图谱
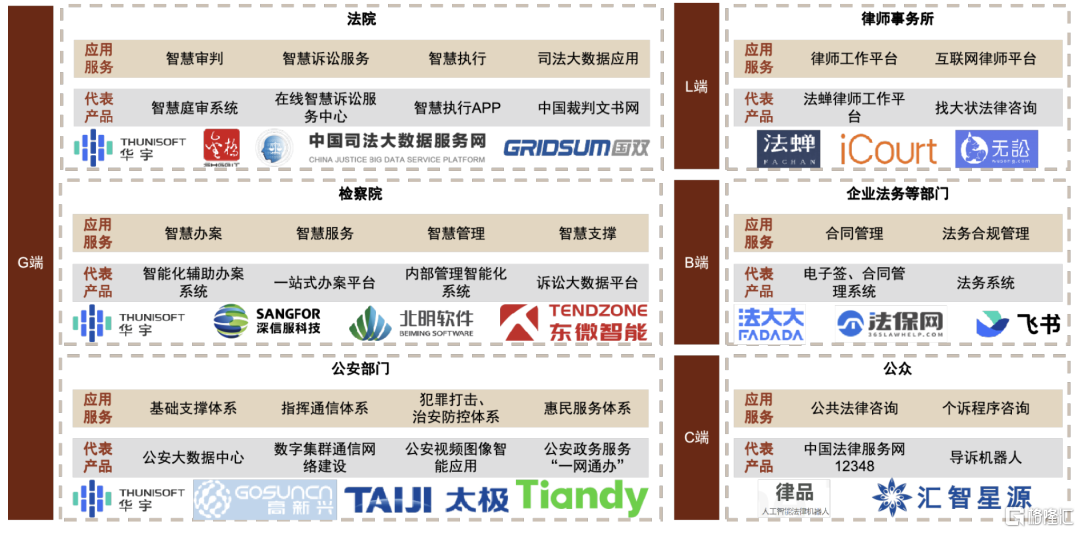
资料来源:中国法院网,最高人民法院官网,“十四五”国家信息化规划,各公司官网,中金公司研究部
法律科技行业市场广阔,在技术、数据等催化下有望保持高增长。根据Houlihan Lokey,全球法律科技行业2019-2025年市场空间预计复合增速为6.4%,从173亿美元增长至252亿美元,增长源自云计算和AI技术发展、法律业务数据量级增长、监管与合规重视程度提升。我们认为国内AI+法律的主要落地场景是法院和律所。法院方面,根据《人民法院信息化建设五年发展规划(2021-2025)》,人民法院将进一步推进智慧法院建设,各级人民法院智慧法院产品渗透率有望进一步提高。律师事务所方面,基于GPT开发的AI文件处理工具以及虚拟法务助手正逐渐引起市场关注,我们认为有望加速律师法务工作信息化、智能化进程。
通用大模型:适配多类从业人员,提供细分功能服务
通用大模型能够适配多种法律场景、服务多类从业人员。通用大模型(后文所称的“大模型”均代指通用大模型)具有广泛的知识储备和语言理解能力,可以处理法律概念、术语和案例法。此外,大模型在处理语言任务时具备较强推理和逻辑能力,帮助从业人员进行法律分析和判断。基于此,大模型能够服务多类机构、人群,包括:律师及律所、法官及法院、公众等。
图表3:大模型在法律场景的应用

资料来源:锦天城事务所官方公众号,中金公司研究部
律师及律所:大模型能够理解复杂的法律术语和概念,生成法律文本,在自动化法律研究和起草、审查法律文件方面提供帮助。1)法律研究:大模型可以通过快速提取和归纳法律条款、案例和相关信息,并提供法律概念解析、法律适用性讨论等建议,帮助律师及律所进行法律研究分析。2)起草、审查法律文件:大模型能够根据律师提供的法律信息和文字指导,生成符合法律要求的文件初稿。例如,锦天城事务所[3]大模型能够用于合规性检查,通过对比法条和文件内容,识别文件中的潜在矛盾之处,并提供合规性建议。
法官及法院:大模型能够通过法律条款和判例的检索、归纳和分析等方式,提升法官判决和法院庭审效率。1)辅助判决:大模型根据案件关键词等信息,归纳概括历史案例、引用法条和判决结果,推理出可能的判决方向和案件结果,辅助法官完成判决。2)辅助庭审:基于大模型的多模态能力,能够整合庭审语音,并生成符合法院要求的相关文书。
公众:大模型具备文本生成和语言合成能力,实现智能问答系统,为公众提供法律咨询服务和纠纷调解服务,帮助用户保障自身权益。公众可以向通用大模型提出一般性的法律问题,模型将通过检索或者根据训练数据提供相关的法律知识和解释,帮助公众更好地理解专业的法律概念和条款,获得普惠的法律咨询服务。
我们认为通用大模型在法律场景的应用或仍存在一些问题:1)特定行业知识储备不足:法律垂类大模型聚焦于专业领域,通用大模型可能存在法律专业知识储备不足的问题。2)可信风险:法律具有严谨、精确、复杂的特点,如果通用大模型训练数据存在偏差、推理缺乏约束,可能导致生成结果的准确性、可靠性较低。3)数据隐私、安全问题:法律案件涉及隐私数据和敏感信息,对于数据安全和信息加密的要求较一般大模型的要求更高。因此,我们认为通过训练精调和功能拓展的法律垂类大模型仍然是有必要的。
法律垂类大模型:训练微调+闭源数据,实现模型性能突破
为什么需要法律垂类大模型?
► 提供法律领域专业数据的价值,提高训练集法律信息密度。通用大模型的训练集中法律信息只占少部分,而垂类大模型可以在通用的训练数据集上增加公开的法律数据,如法考数据、法律法规、司法解释等,法律数据库提供商还可以将数据库数据加入训练。
► 提供符合本地法律特征的数据,提高结果与本地的匹配性。不同国家地区的法律服务匹配不同的法律法规与法律理念,其他法律结果不能直接应用于本地的法律。垂类大模型可以将本地法律特征引入训练、推理过程,提高结果匹配度。
► 引入法律专家的人工标签,提升训练集质量。通过法律专家为数据打标签,能够为训练过程提供专业性背景知识。如Casetext引入专家团队为训练提供大量人工标签数据,并对输出结果进行过滤、排名和评分,更有利于模型学习到正确答案的形式。
过去法律科技公司可以根据解决的问题分为九类。根据斯坦福大学法学院CodeX Techindex法律科技垂类数据库统计,全球法律科技公司可以根据其服务类型分为九类。自2008年以来,海外法律科技公司进入快速发展期,初创公司数量于2015年到达峰值249家。此后法律科技初创公司数量出现回落,直到近年GPT等大模型技术快速落地,法律市场服务、智能生成文书类法律科技公司又重新进入快速发展期,2021年在初创法律科技公司中占比分别提升到24.4%/22.2%。
图表4:斯坦福大学对于法律科技公司的分类

资料来源:斯坦福大学法学院CodeX Techindex法律科技公司数据库,中金公司研究部
不同类别法律科技公司在不同环节提供价值。律师提供的服务可以分为诉讼服务和非诉讼服务,其中合同相关类工具主要在非诉讼业务中提供价值,一些软件则为诉讼流程提供不同价值,包括诉讼前的相关案例准备、诉讼过程中的电子搜证和数据分析等等。此外,法律市场还包括法律服务的需求方,即公众、公司,法律市场服务公司提供了律师与需求方之间的中介平台服务,而业务管理软件为律师管理业务提供了便利。
图表5:不同类别法律科技公司在不同环节提供价值。
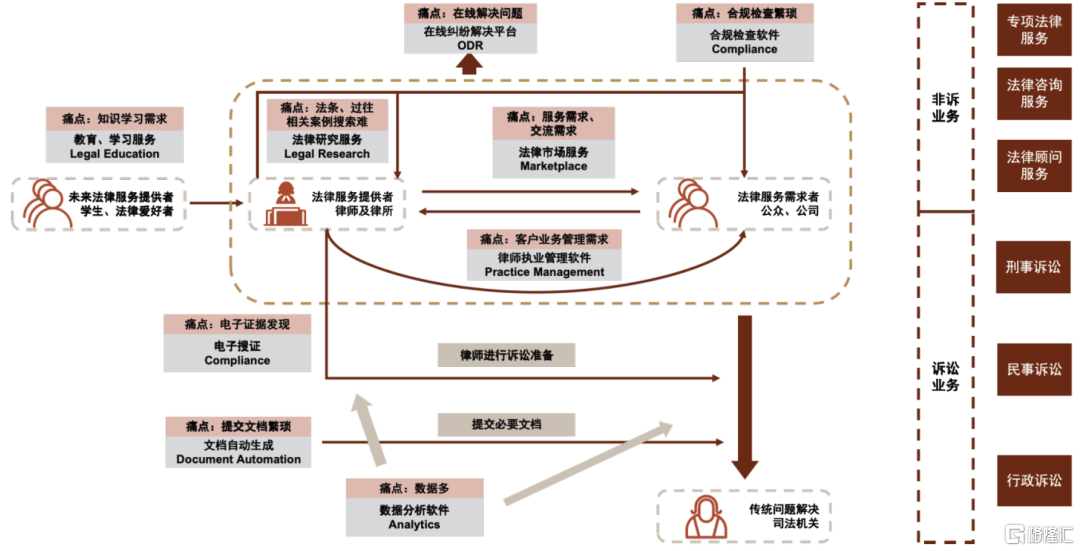
资料来源:斯坦福大学法学院CodeX Techindex法律科技公司数据库,中金公司研究部
基于法律国际化和本土化的双重属性,法律科技产品需要切实服务当地市场需求。由于法律的独特属性,法律科技产品不仅需要实现当地法律信息收集,也需要切实服务法律人士业务需求,关注当地产业升级带来的法律合规管理挑战,例如Lexis公司同金杜、君合等国内知名律所合作打造汽车行业法律风险数字化产品[4]。
法律行业垂类大模型,相较于通用大模型,提升对法律专业知识的认知理解和法律文本生成的准确性。法律行业垂类大模型在大模型的基础上,在训练阶段使用专业法律指令数据集微调通用大模型,并在推理阶段提升指示词质量,解决通用大模型在法律领域存在专业知识储备不足和生成结果失真等问题,以更精准的理解法律概念和生成法律文本,满足法律各类从业人员的工作需求,提供高效便捷、颗粒度更细的功能服务。
我们以华宇软件发布的“万象”法律大语言模型[5]、北京大学发布的Lawyer LLaMA[6]和ChatLaw[7]、科大讯飞发布的星火法律大模型[8]、卡耐基梅隆大学发布的Augmented LLM[9]以及汤森路透发布的Fine-tuning LM[10]为例,介绍学术界和业界发布的法律垂类大模型相比通用大模型在数据、算法层面的微调和突破,分析法律垂类大模型如何与法律应用场景相适配。
图表6:部分国内外法律大模型

资料来源:华宇软件微信公众号,科大讯飞微信公众号,arXiv,中金公司研究部
训练阶段:使用专业法律语料库微调通用大模型
汤森路透实验室使用COLIEE训练集[11]对GPT-3模型进行微调。通过使用特定于法律任务的数据集COLIEE进行训练,来更新预训练语言模型的参数权重。该数据集使用了日本法律考试的部分试题,包含对特定法律陈述的正误判断。汤森路透分别将两类COLIEE数据加入GPT-3模型进行微调:1)包含正误判断与伪解释[12]的二元化数据集,2)包含正误判断与GPT-3模型自生成解释的数据集。实验结果显示,经过数据集1微调的GPT-3模型精度提升23.99%,使用数据集2微调的GPT-3模型精度并无明显改善。使用包含有人工参与的伪解释处理的二元化数据集的训练效果,要好于GPT-3自生成解释的数据集的训练效果,我们认为法律大模型的训练数据集仍然需要专业人员进行数据集的处理和优化。
图表7:使用数据集1的微调流程
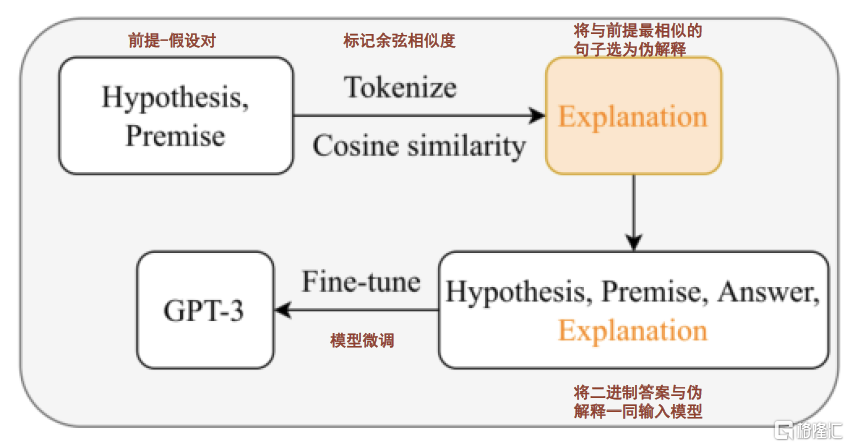
注:数据集1中包含True/False二进制答案与根据相似度选定的伪解释资料来源:Fangyi Yu,et al. Legal Prompting: Teaching a Language Model to Think Like a Lawyer[J]. arXiv:2212.01326v2 [cs.CL]8 Dec 2022, 中金公司研究部
图表8:使用数据集2的微调流程

注:数据集2中包含True/False二进制答案与GPT-3模型自生成的解释
资料来源:Fangyi Yu,et al. Legal Prompting: Teaching a Language Model to Think Like a Lawyer[J]. arXiv:2212.01326v2 [cs.CL]8 Dec 2022, 中金公司研究部
在模型训练阶段,使用中文法律数据构建指令数据集,对通用大模型进行微调。由于GPT等通用大模型训练使用的中文语料较少,且公开数据中包含的法律信息准确性、规范性等难以保证,因而需要构建中文法律指令数据集对大模型进行微调。该阶段最核心的工作是构建专业、准确、全面的中文法律指令数据集,包含法律知识、判决案例、法律问题和解答等信息。
“万象”法律大模型利用自建数据集,对通用大模型进行精调训练和迭代升级。在统一调度层,该模型通过输入高质量、和业务场景匹配的指令训练集对大模型进行精调,利用覆盖法律全业务场景的测试集对大模型的回复结果进行验证,并依据验证结果对大模型进行迭代,从而是实现从通用大模型到法律大模型的升级优化。
► 指令训练集:基于法律专家对业务场景的理解构建的高质量、多场景、专业化的指令集,覆盖法律事实定性、法律识别、案例信息解构、文书初稿生成和法律条文理解等。
► 测试集:基于客户、合作伙伴和华宇法律研究院构建的一套覆盖法律全业务场景的测试集,对大模型的回复结果进行自动化或法律专家验证,从而把握法律大模型质量。
图表9:“万象”法律大模型构建——精调训练
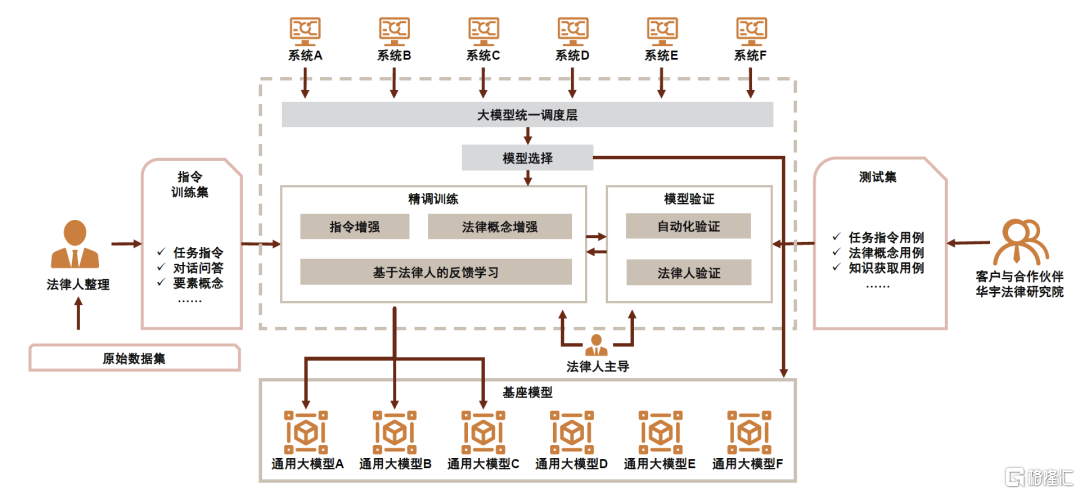
资料来源:2023法律科技大会,中金公司研究部
Lawyer LLaMA使用法考数据集、法律咨询数据集,提升模型在法律问题解答、法律知识和解题技巧、法律咨询的能力。1)JEC-QA中文法考数据集:包含26,365个多选和开放式问题,模型将这些问题作为指示输入ChatGPT,构建包含问题、生成答案和解释的法考数据集。2)开源法律咨询案例:研究人员收集了单轮回答和多轮对话的数据,并使用ChatGPT生成包含引用法律文章、基于案件事实和法律文章进行充分分析、全面回应并分析可能的可能性、适时提问以获取更多事实、使用简明语言、给出初步的法律意见和咨询结论的答案。
ChatLaw的指令数据集由公开和私有数据两部分组成,经过严格数据清洗提升数据质量。1)公开数据集:包含论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书等数据,过滤简短、不连贯的回答,只保留高质量、有意义的文本。2)私有数据集:与北大国际法学院和部分行业律师事务所合作,提供私有高价值数据并把关数据质量。
图表10:Lawyer LLaMA训练过程
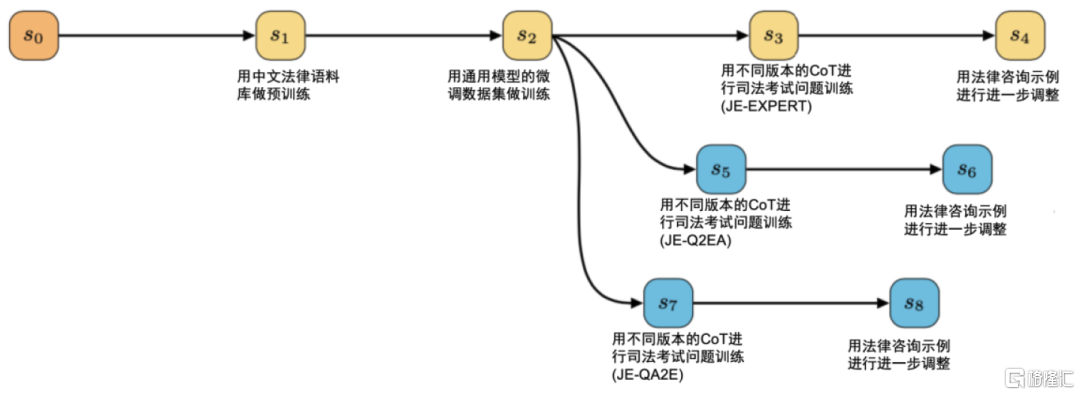
资料来源:Huang, Quzhe, et al. "Lawyer LLaMA Technical Report." arXiv preprint arXiv:2305.15062 (2023).,中金公司研究部
推理阶段:调整指示词质量提升大模型性能
提示词质量可以对大模型响应结果形成直接影响。提示词(Prompt)指用户输入给大模型,让其完成特定任务的自然语言文本,包括问题、文本、指令等。大模型生成内容时,会先对输入指示词进行处理,再根据对提示词的理解预测下一个词出现的概率,进而逐字进行输出。因此,高质量的提示词可以最大化大模型潜力,减少语言表达不清晰所导致的错误,引导其精确理解任务并生成准确、有价值的内容。
图表11:Prompt工作原理
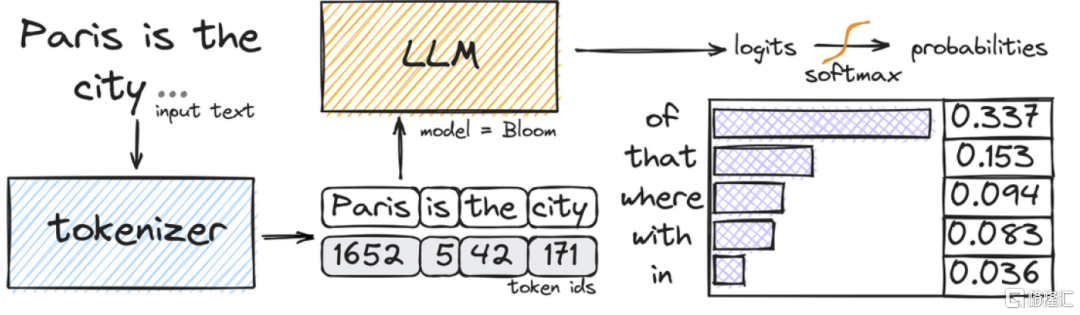
资料来源:腾讯云,中金公司研究部
在模型推理阶段,通过提示工程最大化预训练模型性能。提示工程(Prompt Engineering)指通过提示词的开发和优化,将一个或多个任务转换为“基于提示的数据集”,在无需更新的情况下提高大模型能力,引导其生成结果的准确度和相关性。
法律领域数据量大且专业性强,可以通过调整提示工程的路径完善法律知识。根据Lawyer LLaMA技术报告[13],尽管大模型在训练阶段学习了大量的法律数据,在生成响应时仍存在难以正确地使用法条、引用错误法律文章、使用相似语义的法律概念等问题。此外,法律领域数据量较大且覆盖范围广,预训练模型难以涵盖所有数据。研究表明1个提示词相当于100个真实数据样本[14],推理阶段调整提示词可以进一步补充专业的法律知识和规范写法,增强模型在垂类领域的理解和推理能力,使其产生更加可靠的回答。
当前法律垂类大模型主要在训练和推理阶段对通用大模型进行微调。在训练阶段使用专业法律指令数据集微调通用大模型,提升垂类大模型对法律知识的理解,并在推理阶段提升指示词质量,尽可能发挥垂类大模型在法律文本生成的性能。
海外AI+法律:多元化应用,高潜质赛道
他山之石:海外AI+法律应用落地加速,市场关注持续升温
近年法律科技公司融资热点集中在虚拟法务助手、智能文书处理等领域。根据我们的不完全统计,目前全球已有多家公司基于GPT模型成功开发AI+法律产品。多数产品利用GPT出色的自然语言处理能力,帮助律师或公司法务团队高效完成文书处理工作。
但是形态较单一、功能较简单的AI+法律产品,无法为法律工作者提供场景化服务。针对以上痛点,目前海外已有Casetext、Harvey、LexisNexis等法律科技服务商开发虚拟法务助手,力图为法律工作者提供多维、专业的AI法律服务能力。在功能上,虚拟法务助手产品不仅几乎覆盖所有智能文书处理功能,还独具陈词建议、法律研究等强专业性技能,能够更好满足法律从业者的工作需求。在服务上,虚拟法务助手支持自然语言对话,用户可以更加便捷地提出个性化需求,获得全流程的法律工作支持。我们认为虚拟法务助手产品有望引领AI+法律未来发展方向。
图表12:2023部分新获得融资法律科技公司AI产品功能汇总

注:根据公司官网整理,统计截至2023年12月末,仅统计部分公司产品功能作为展示,存在不完全统计 资料来源:公司官网,中金公司研究部
2023年以来海外法律科技公司融资活跃。根据我们的不完全统计,2023年以来海外已发生多起法律AI相关融资事件。融资轮次多发生在早期阶段,初创公司产品功能集中于文件起草、合同起草、虚拟法务助手等领域。其中,Harvey在继创立之初收获OpenAI Startup Fund的500万美元融资后,2023年获得来自红杉资本领投的2100万美元A轮融资;研发出虚拟法务助手CoCounsel的Casetext也于2023年6月被汤森路透以6.5亿美元收购。
图表13:2023海外法律科技融资情况(不完全统计)
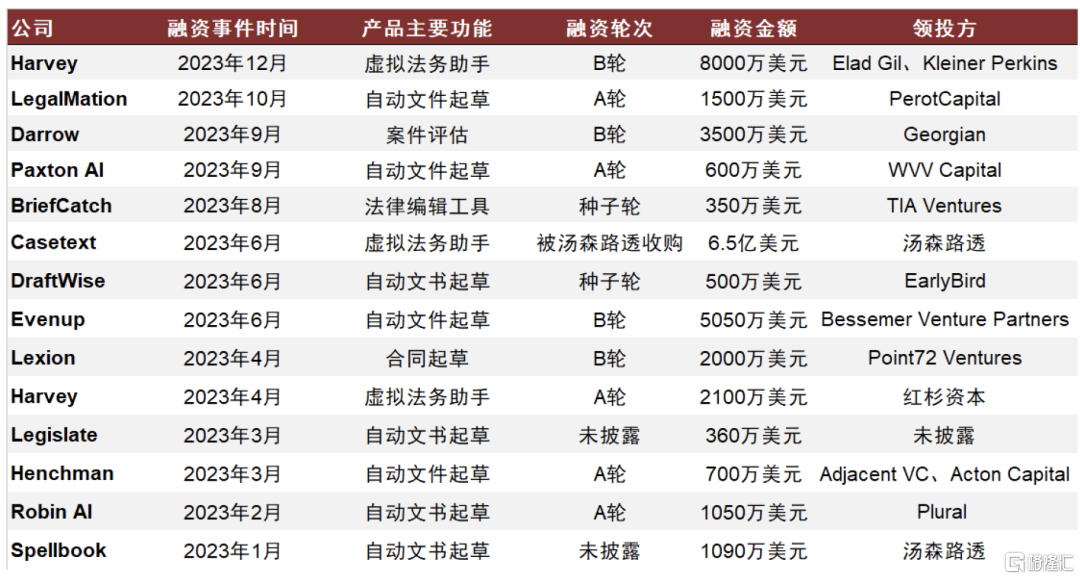
资料来源:Legal IT Insider、Legalcomplex、Seedtable、各公司官网,中金公司研究部
海外法律AI产品形态以ToB为主,目标客户多为律师、公司法务团队,收费模式上License模式、SaaS模式并存。公司多与律师事务所达成合作协议进行批量试用或采购,Casetext在其官网展示的标杆客户包括Dykema[15]、DLA Piper[16]、Troutman Pepper[17]等知名律师事务所,官网披露CoCounsel已在10,000家律师事务所得到试用,其他试用客户还包括财务50强公司和非营利组织的法务部门。Harvey的A轮融资领投方红杉资本也发文称已有15,000家律师事务所等待使用Harvey产品。收费模式方面,由于部分产品仍处于demo阶段,并未公布具体收费计划。在已经公布的产品中,Summize、Henchman、Evenup通过出售软件使用许可证收费,Contract Works、CoCounsel、Lexis+AI收取SaaS服务年费。
图表14:发布“GPT+法律”产品的海外公司

资料来源:Legaltech Hub,各公司官网,中金公司研究部
风险提示
国内法律垂类大模型落地应用不及预期。行业垂类大模型作为新兴技术,仍属于模型训练和产品研发、试用阶段,若技术在下游场景应用能力不及预期,可能导致落地进度放缓。
行业竞争加剧。除成熟法律科技公司外,初创科技公司、互联网公司凭借技术优势参与布局法律行业应用,未来行业竞争可能进一步加剧,市场格局可能发生改变。
本文摘自中金公司2024年3月25日已经发布的《人工智能十年展望(十八):AI+法律,法律智能化与创新》
分析员 车姝韵 SAC 执证编号:S0080523050005 SFC CE Ref:BTM272
分析员 于钟海 SAC 执证编号:S0080518070011 SFC CE Ref:BOP246
联系人 童思艺 SAC 执证编号:S0080122070064
分析员 魏鹳霏 SAC 执证编号:S0080523060019 SFC CE Ref:BSX734



