下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
在最近与投资者的交流过程中,我们发现部分投资者在与大模型相关的几个关键问题上存在一些分歧,故本文希望针对这些问题谈谈我们的认识。
问题一:哪些场景会是我们需要重点关注的潜在应用场景?
寻找大模型时代的原生应用。目前市场中寻找大模型落地场景的方式基本上是基于以往场景的线性外推,即“怎么样把已经能做的事情做得更好”。但事实上,以往的每次技术革新最终都带来了一些“原生”的产品形态和落地场景。我们认为,相对于对于原有产品的赋能,大模型更大的价值或许在于帮助我们解决一些之前无法解决的问题(包括此前由于技术或成本方面的原因无法解决的问题)。就像移动互联网的杀手级应用都是在新的时代“原生”的,而不是从PC互联网迁移过来的。

在等待大模型商业落地的过程中,我们不必过于悲观。毫无疑问,任何一项技术的商业落地都不是一蹴而就的,并不像部分投资者想得那样,这个月研发大模型,下个月就直接产生收入。在这个过程中,大模型落地的“慢于预期”实际上更多来自于我们自身心态的变化。就像我们常常听到的一句话:“当一项技术诞生的初期,我们往往会高估它的短期影响,而低估它的长期影响。”在最初的过度亢奋之后,我们往往又对技术的落地前景过于悲观。
在报告《寻找AI技术潜在应用场景的方法论是什么?》中,我们已经给出了寻找AI潜在落地场景的方法论,这里不再赘述。仅就一个有意思的问题做补充探讨。
在之前的报告中,在我们从“商业价值的大小”、“数据获取难度”两个维度对场景进行了划分,并指出对于一般公司而言(相对于BAT等互联网巨头与科大讯飞等垂域领域巨头而言),潜在机会可能更多地来自于长尾场景。
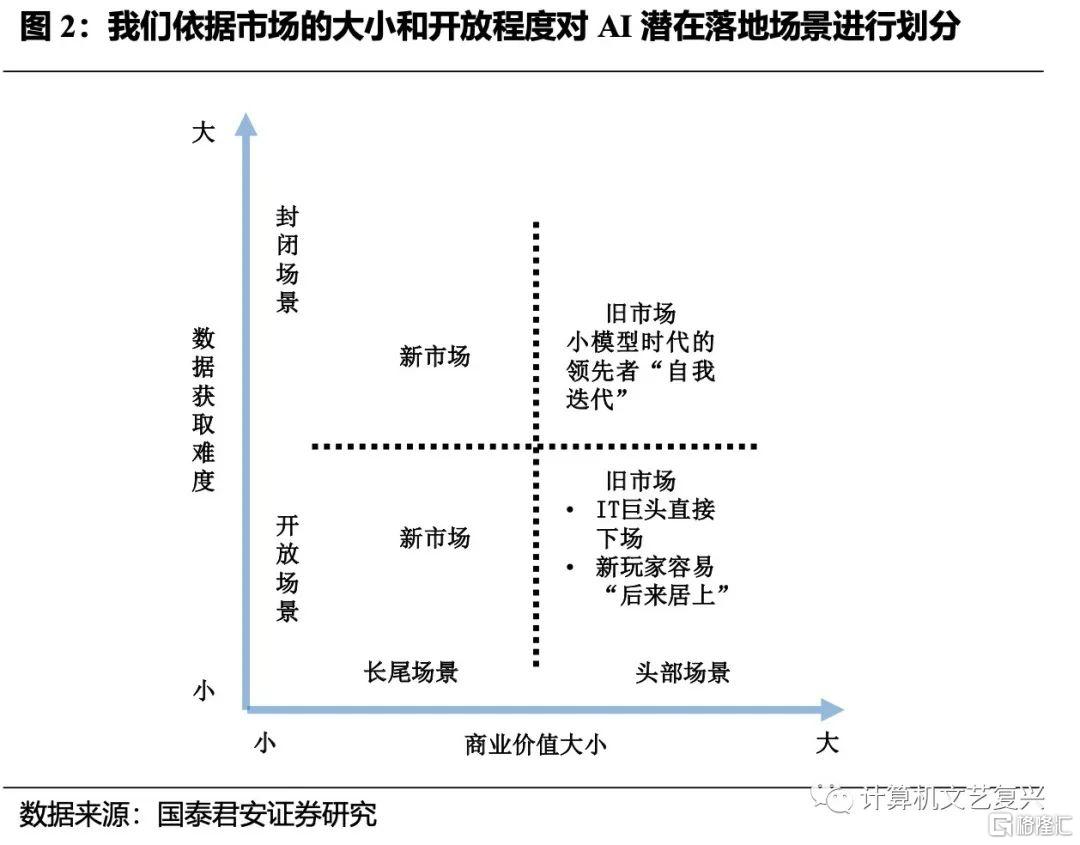
那么对于“第二象限”,即“封闭场景——长尾场景”象限和第三象限即“开放场景——长尾场景”象限来说,哪类场景是更好的潜在方向呢?我们认为是第二象限。原因在于:
第二象限的“封闭”特性意味着相对于模型能力而言,数据获取能力更重要,渠道和行业语料的拥有者会有更强的话语权。而对于一个开放性的场景来说,大模型厂商话语权更重。在这类场景中,“被赋能企业”只有不断产生新的应用创意才能持续保持竞争力,否则就有被大模型厂商吃掉的风险,或面临市场上同类产品的同质化竞争。而持续产生新的创意显然并不容易。

问题二:大模型的主要意义是否在于提升解决问题的准确度?
相对而言,提升解决单点问题的准确度或许是大模型带来的“不那么重要”的提升。因为无论是大模型还是场景化模型,依然是基于统计学框架,暂时无法彻底解决AI能力的不可解释性问题,这就意味着它在一些对于corner case敏感的场景下落地仍旧会非常受限。因为本质上来说,这是一个技术和伦理的问题,在这类场景中98%的准确度和95%的准确度并没有本质差别。
那么,除了提升准确度之外,大模型的潜力还在于哪些方面呢?
第一,大模型可以帮助我们解决一些此前无法解决的单点问题。这在上文中已有讨论,这里不再赘述。
第二,大模型有望彻底改变IT开发范式,提升垂域产品的标准化程度。在很多垂域的场景中,客户的需求虽然大体类似,但仍然存在着一定的差异,比如客户自身的业务流程不同,或是IT建设的侧重点不同等等。这就导致在为这些客户进行IT能力建设的时候,会产生大量的定制化工作,使得IT厂商的规模效应大打折扣。随着大模型的落地,后续客户的数据或将可以通过插件的模式接入大模型,前端的整体交互可以直接通过自然语言的方式来实现,这就意味着一些垂域软件的标准化程度有望大幅提升。

问题三:“千模大战”是否意味着每个公司都能做大模型?
最近和投资者的交流中,我们发现了一个非常有意思的观点:随着大模型相关的发布会越来越多,部分投资者直观上认为每家公司都可以做大模型。
而在我们看来,情况并非如大家所想。构建一个好的大模型仍然有诸多壁垒,包括但不限于:
资本开支:这是最显而易见的一个壁垒。众所周知,训练一个百亿参数的大模型,需要几百张GPU卡,每张卡7万,那就意味着构建集群的成本就是千万到数亿元的投入。如果训练的是千亿参数的模型,则需要千卡集群。很显然,这方面的投入并不是每个厂商都有实力去做的。而且,在训练过程中对于云资源的调用也会消耗大量成本。
工程化能力:目前外界对于GPT系列模型的研究基础主要基于Open AI关于Instruct GPT的一篇论文。在GPT-3、Instruce GPT及以前的版本中,Open AI对于GPT的技术是完全开源的,而且公开发表的论文中表述非常详细,包括做GPT模型的思路、所用的数据集是什么等等。但从达芬奇模型开始(code-davinci-002,2022年Q1左右),GPT系列走向了闭源。单纯从技术上来讲,Open AI此前已经公开了它的主要思路,那么为什么其他厂商暂时还没有实现完全意义上的复刻?其中一个重要的原因就在于,Open AI不公开它的数据工程方面的信息,比如如何获取数据,数据训练是怎么做的,怎样投喂到模型中等等。所以,虽然模型本身并没有那么强的壁垒,但是如何训练和处理数据,是包含了非常多的工艺技巧的,也就是我们经常提到的工程化能力。
问题四:大模型所带来的“技术平民化”趋势是否会让场景化模型时代领先的玩家被快速颠覆?
我们认为,并不会。
从技术角度,“模型微调”其实包括两层内涵。
第一层是用SFT的数据做fine-tune,其中SFT数据就是那些问答对。在这个过程中,模型习得的其实并不是某个行业的深入知识,而是一种更符合人类期望的回答模式。在这个过程中,我们需要的问答对的数量往往不会很大。根据我们产业调研的结果,训练一种全新的能力,基本上只需要千条级别的问答对。
第二层是在预训练的过程中,投喂大量的某行业的语料对模型进行进一步地训练。在这个过程中,为了使得模型掌握该领域的行业知识,我们需要投喂对应领域大量的语料进行训练,同时还需要保证所投喂语料的质量,否则同样会影响模型蒸馏的效果。
“模型蒸馏”仍需要一定体量的行业数据。根据我们产业调研的结果,需要同时使用上述两种方式,才能在把大模型“蒸馏”成行业模型的过程中获得比较好的效果。这就意味着“模型蒸馏”的过程依然会对行业数据有大量的需求。
而很显然,并不是每个行业的行业语料都是容易获得的。在我们此前的报告中,把这一问题归结为了“场景开放性”的问题(详见报告《AI大航海时代的数字罗盘》),这里我们仅作简要陈述。
在开放场景中,“模型蒸馏”所需要的数据可以通过公开手段获得。包括传统或者新兴的消费电子单品所衍生出来的各种应用,比如手机上的生态软件、智能音箱上的软件等等。这些是都是典型的“开放场景”。使用者使用某个产品后数据直接沉淀在了产品终端或后台。
在封闭场景中,数据和特定类型的机构深度绑定,“模型蒸馏”所需要的数据不容易获得,数据和渠道比模型能力本身更重要。2B或者2G的垂直领域中的很多细分赛道是“封闭场景”,比如医疗、教育、政法、工业等等。在这类场景中,数据是和特定类型的机构深度绑定的,以至于对于新进入者来说数据获取难度很大,而且难以在短时间内构建起和客户之间的信任关系,“数据获取能力和渠道优势”占据主导,小模型时代的领先者利用大模型实现“自我迭代”的概率更高。
问题五:同时拥有大模型和垂域场景数据的公司有何优势?
在我们讨论大模型对行业赋能的时候,天然就把公司分为了大模型厂商和被赋能厂商两类。但我们认为,同时拥有大模型和众多垂域场景数据的公司或更有稀缺性,其竞争优势至少来自于以下几个方面:
第一,配合度优势。
我们认为,虽然目前大模型仍处于“千模大战”的阶段,但随着时间的推移,必将有绝大多数厂商退出竞争,大模型最终仍将是巨头的游戏。这就意味着,最终可以选择的大模型并不多。
在这个阶段,大模型厂商已经建立起了生态、技术、成本等诸多壁垒,话语权随之上升。在这种情况下,对于某个特定的垂域客户来说,寄希望于大模型厂商针对其进行模型的“蒸馏”和训练是不切实际的。
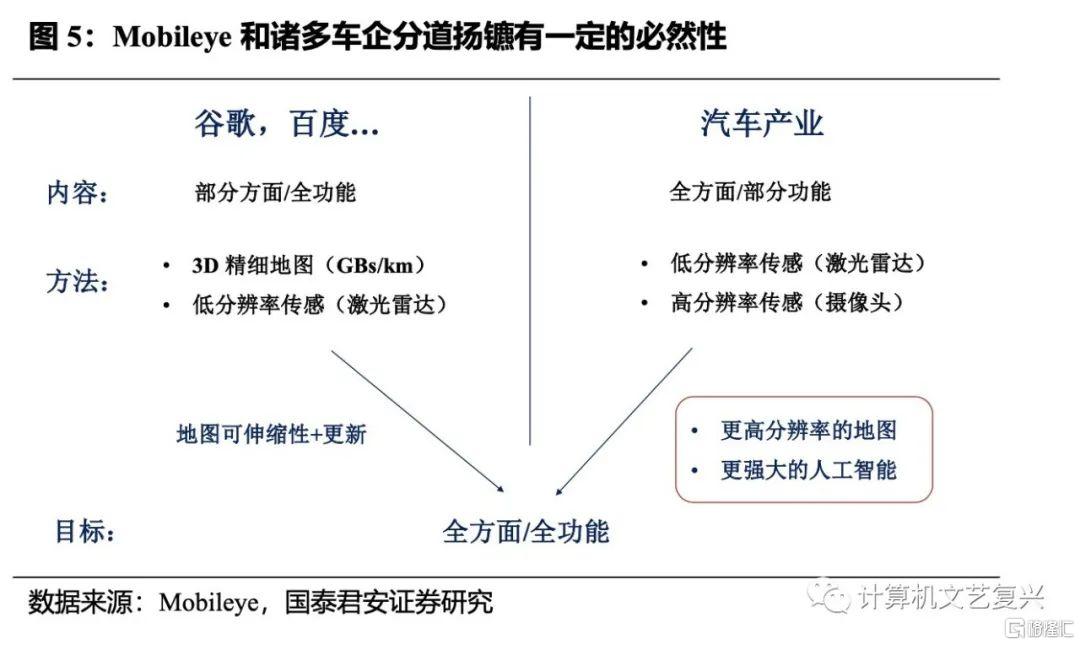
这里可以引入一个自动驾驶行业的例子进行类比。在ADAS的时代,Mobileye占据了全球绝大部分的份额,这就意味着它需要同时服务全球诸多的主机厂,不论是从主观上还是客观上都难以针对每个主机厂的需求进行及时有效的配合。可以说,正因为在上一个阶段的强势,导致Mobileye在近几年逐渐式微。
此时,对于同时拥有大模型和垂直行业场景的公司而言,两个团队的配合属于公司内部的资源调度,资源的调配难度明显更小。
第二,迭代效率的优势。在利用大模型进行“蒸馏”得到行业模型的过程中,大模型和行业模型之间是存在一定程度的“耦合”的。也就是说,当基础大模型进行版本更新后,如果不对行业模型进行重新的迭代,最后产生的效果可能会反过来由于大模型的升级而变差。而对于同时拥有大模型和垂直行业场景的公司而言,在迭代效率方面具有明显优势。
第三,差异化竞争的优势。有一句经常被投资者提起的话:“当所有公司都受益时,就意味着可能没有公司真正受益。”在最初阶段,一个垂域场景中的不同公司由于对于大模型的接受程度和接入速度不同,其产品竞争力的对比可能会发生变化。但从长远来看,在最终胜出的几家大模型厂商的技术没有代差的情况下,大模型对于行业格局的影响或趋于弱化。即最终受益者或许是大模型厂商和终端消费者,但垂域厂商在商业上并不一定会受益。而对于同时拥有大模型和垂直行业场景的公司而言,将不需要面对同质化竞争的问题。
注:本文来自国泰君安发布的《关于AI大模型的五个关键问题 | 国君计算机》,报告分析师:李沐华、齐佳宏
本订阅号不是国泰君安证券研究报告发布平台。本订阅号所载内容均来自于国泰君安证券研究所已正式发布的研究报告,如需了解详细的证券研究信息,请具体参见国泰君安证券研究所发布的完整报告。本订阅号推送的信息仅限完整报告发布当日有效,发布日后推送的信息受限于相关因素的更新而不再准确或者失效的,本订阅号不承担更新推送信息或另行通知义务,后续更新信息以国泰君安证券研究所正式发布的研究报告为准。
本订阅号所载内容仅面向国泰君安证券研究服务签约客户。因本资料暂时无法设置访问限制,根据《证券期货投资者适当性管理办法》的要求,若您并非国泰君安证券研究服务签约客户,为控制投资风险,还请取消关注,请勿订阅、接收或使用本订阅号中的任何信息。如有不便,敬请谅解。
市场有风险,投资需谨慎。在任何情况下,本订阅号中信息或所表述的意见均不构成对任何人的投资建议。在决定投资前,如有需要,投资者务必向专业人士咨询并谨慎决策。国泰君安证券及本订阅号运营团队不对任何人因使用本订阅号所载任何内容所引致的任何损失负任何责任。
本订阅号所载内容版权仅为国泰君安证券所有。任何机构和个人未经书面许可不得以任何形式翻版、复制、转载、刊登、发表、篡改或者引用,如因侵权行为给国泰君安证券研究所造成任何直接或间接的损失,国泰君安证券研究所保留追究一切法律责任的权利。