 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
RISC-V这几年风潮正盛,而RISC-V内核应用最广的则是MCU。尤其是国内的MCU厂商对RISC-V的追捧程度可见一斑,基本上知名的MCU厂商都有RISC-V的方案。凭借指令集少、开源等的优点,RISC-V也给了国产MCU赶超国际大厂的机会。但是现在,我们看到,RISC-V的触角正在不断蔓延,从最开始的MCU逐渐来到加速器、CPU、AI处理器甚至是GPU。
RISC-V被用作加速器
现在RISC-V越来越多的被用作加速器。欧洲成立的EPI项目的一个关键部分是开发和演示基于 RISC-V 指令集架构的完全由欧洲开发的处理器 IP,提供名为 EPAC(欧洲处理器加速器)的高能效和高吞吐量加速器内核。就在近日,EPAC1.0 RISC-V 测试芯片样品已交付给 EPI 并且其操作的初步测试成功。
EPAC 结合了多种专门用于不同应用领域的加速器技术。下图所示的测试芯片包含四个矢量处理微瓦(VPU),由SemiDynamics设计的Avispado RISC-V内核和巴塞罗那超级计算中心和萨格勒布大学设计的矢量处理单元组成。每个 tile 还包含一个 Home Node 和 L2 缓存,分别由 Chalmers 和 FORTH 设计,提供了内存子系统的连贯视图。该芯片还包括两个额外的加速器:由 Fraunhofer IIS、ITWM 和 ETH Zürich 设计的 Stencil 和 Tensor 加速器 (STX),以及由 CEA LIST 设计的精度可调处理器 (VRP)。片上的所有加速器都与 EXTOLL 的超高速片上网络和 SERDES 技术相连。

EPAC测试样品
初始启动成功,EPAC 执行了它的第一个裸机程序,发送传统的“Hello World!” 用不同的语言向 EPI 财团和世界致以问候。
成立于2018年的初创公司Ventana Micro Systems 看到了强大的RISC-V服务器业务的窗口。Ventana 创始人兼首席执行官 Balaji Baktha 表示:“近一半的计算支出正在从通用处理器转向基础设施计算和特定领域的加速器。“凭借我们基于可扩展 RISC-V 架构的高性能内核以及我们基于小芯片的快速产品化方法,Ventana 完全有能力利用这一趋势。”
Ventana公司官网中介绍,其RISC-V内核的性能与高端Arm和x86数据中心内核相当,而且独特的微架构创新使其设计可在领先的晶圆厂和工艺节点之间轻松移植。
据透露,其 64 位RISC-V处理器的首批样品有望在明年下半年与客户共享,并在2023年上半年量产。据The Register的报道,该公司首席执行官兼联合创始人 Balaji Baktha介绍到,他们的新芯片采用Chiplet的方式,即每个芯片将包含多个独立的裸片,包括一些带有 CPU 内核,一些带有自定义加速,另一些带有 IO 和内存接口,然后在单个封装内互连。所有裸片都使用由Ventana设计的互连连接在一起,据说该互连是缓存一致的,访问延迟为8ns,并且每条通道最多可移动 16Gbps。这家初创公司认为这将适用于连贯地连接 CPU 内核、加速芯片、片上存储以及与片外 RAM、PCIe 设备和其他 IO 通信的接口。
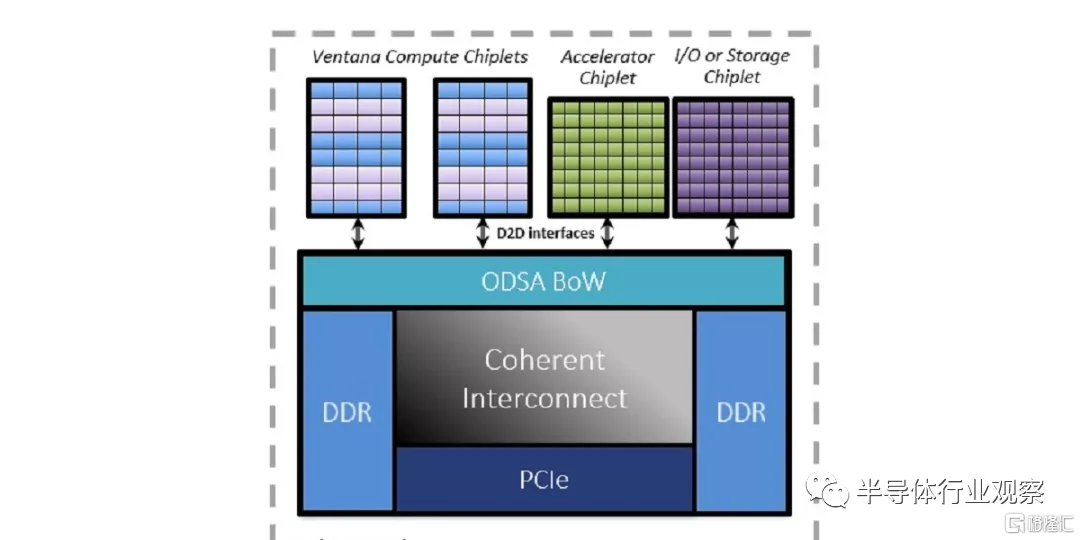
按照他们的规划,计算和 IO 芯片将由Ventana设计,定制加速芯片将由客户提供,而整个产品由 Ventana 使用其代工厂合作伙伴为其封装。一个处理器封装中最多可以放置六个小芯片。客户只需确保自己的定制芯片设计符合互联规范就可以直接投入使用。
与流行的IP模型相比,Ventana 的模块化、可扩展的基于小芯片的产品策略可显着减少开发时间和成本。虽然 Ventana 的计算小芯片通过针对尖端工艺几何形状来最大限度地提高性能,但客户可以在目标应用的最佳工艺节点中实施其独特的 SoC 小芯片硅。为确保互操作性,Ventana 提供了一种并行芯片到芯片 (D2D) 解决方案,能够实现极低的延迟、高带宽和最低功耗。D2D 解决方案符合 OCP Open Domain-Specific Architecture (ODSA) 物理接口标准。
预计这些芯片最开始将用于诸如控制和数据平面处理器、安全和存储设备的片上系统、用于构建大量自己的服务器和数据中心的超大规模企业和类似企业,并希望在芯片级别包含特定功能。根据 Baktha 的说法,这些客户被 RISC-V 吸引的原因是一方面,它允许他们使用自己的自定义指令扩展开放的、免版税的指令集架构,以加速特定任务。
RISC-V来到CPU
在CPU领域的应用,中国可谓是走在前列。首先是阿里巴巴于2019年推出了玄铁910,根据阿里巴巴集团副总裁戚肖宁博士公布的资料显示,玄铁910基于当下非常热门的RISC-V开源架构开发,是一款高性能CPU,可以以IP Core的形式集成到SoC处理器当中。
此外,中科院计算所去年发布了基于RISC-V的香山内核。该内核的第一版微架构雁栖湖在去年6月就建立了代码仓库,并于今年四月完成了RTL工作。雁栖湖采用台积电28nm架构,是一个11级流水线的架构,频率可达1.3GHz,SPEC CPU2006可达7分/GHz左右。第二版南湖架构的设计讨论工作也在今年开始,预计2021年底可以完成。该架构采用中芯国际的14nm工艺,频率预计可以达到2GHz,SPEC CPU2006可达10分/GHz。值得一提的是,基于RISC-V的笔记本有望明年问世。中科院软件研究所计划在2022年底之前打造2000台RV64GC笔记本。
作为全球的做大的CPU领主英特尔正在加入这个行列。据知情人士透露,RISC-V初创公司 SiFive已收到投资者英特尔公司的收购意向。据报道,英特尔宣布将打造自己的RISC-V开发平台,代号为Horse Creek。该芯片有望在 2022 年推出,采用 7nm 工艺。新平台将采用 SiFive P550,这是一种新发布的CPU内核,代表了迄今为止发布的最高性能 RISC-V CPU。
初创公司也开始参与到RISC-V CPU中来。据SemiAnalysis的爆料,一家名为Rivos的初创公司,正在利用RISC-V研制CPU。这家公司的团队成员来自苹果、谷歌、高通、英特尔、Marvel等。SemiAnalysis相信这将是第一个真正高性能的RISC-V设计。
一则苹果招聘广告显示,苹果开始对RISC-V感兴趣。该公司正在探索使用RISC-V芯片。职位要求“成功的候选人将从矢量编程的角度对 RISC-V ISA 架构有很好的理解和知识,以及 ARM CPU 内核中的 NEON 微架构的工作知识。”

虽然有些人认为这表明苹果正在寻求更换基于ARM的处理器,但这种情况极不可能,该职位的范围非常具体。职位描述中指出,程序员将在一个“实施创新的 RISC-V 解决方案和最先进的例程”的团队中工作。这是为了支持机器学习、视觉算法、信号和视频处理等必要的计算,”这项工作在 Apple 的 Vector and Numerics Group 内,该集团在 Mac、iPhone、Apple Watch 和 Apple TV 等产品中设计嵌入式子系统。这可能表明 RISC-V 将用于支持硬件,而不是为计算设备提供动力的主处理器。
欧洲甚至成立了两个关于RISC-V的项目,分别是前文所指的EPI和eProcessor 项目。不同于EPI项目,eProcessor项目旨在构建一个新的开源 OoO 处理器,并提供第一个基于这个新 RISC-V CPU 的完全开源的欧洲全栈生态系统。eProcessor 计划用于数据服务器、高级驾驶辅助系统 (ADAS) 的人工智能 (AI) 和中央汽车 CPU 以及用于手机和物联网中的嵌入式应用的CPU。
此外,RISC-V还可以优化CPU和网络之间绝对时延的确定性问题。斯坦福大学的博士后Stephen Ibanez 在 OSDI '21 会议上提出了 nanoPU 概念。他们提出了一种协同设计的网络接口卡和 RISC-V 处理器,它提供了一条进入 CPU 的快速路径,可以显着降低 RPC 的延迟并同时使它们更具确定性时间。
nanoPU是经过网络优化的新型CPU,旨在最大程度地减少RPC的尾部延迟。通过绕过高速缓存和内存层次结构,nanoPU直接将到达的消息放入CPU寄存器文件中。通过应用程序的线对线延迟仅为65ns,比当前的最新技术快13倍。nanoPU将关键功能从软件转移到硬件:可靠的网络传输,拥塞控制,核心选择和线程调度。它还支持独特的功能来限制高优先级应用程序遇到的尾部延迟。他们的原型nanoPU正是基于改进的RISC-V CPU。
RISC-V开始强攻AI
成立于2014年的Esperanto于2020年12月发布了ET-SoC-1,这是一款基于RISC-V架构的7纳米机器学习处理器。该芯片由台积电制造,拥有 2400 万个晶体管,主要设计用于机器学习推理工作负载。
在最近的 Hot Chips 33线上活动中,Esperanto 创始人兼执行主席 Dave Ditzel 公布了他所谓的片上超级计算机的详细信息,它可以用作主处理器或加速器,旨在适应现有的数据中心需要在风冷环境中提高电源效率。
Esperanto 开发的芯片,其中包含 1,088 个节能的 ET-Minion 有序内核,每个内核都带有一个矢量张量单元,以及四个 ET-Maxion 无序内核。ET-SoC-1 提供超过 1.6 亿字节的片上 SRAM、用于具有低功耗 LPDDR4x DRAM 和 eMMC 闪存的大型外部存储器的接口以及与 PCIe x8 Gen4 和其他 I/O 接口的兼容性。
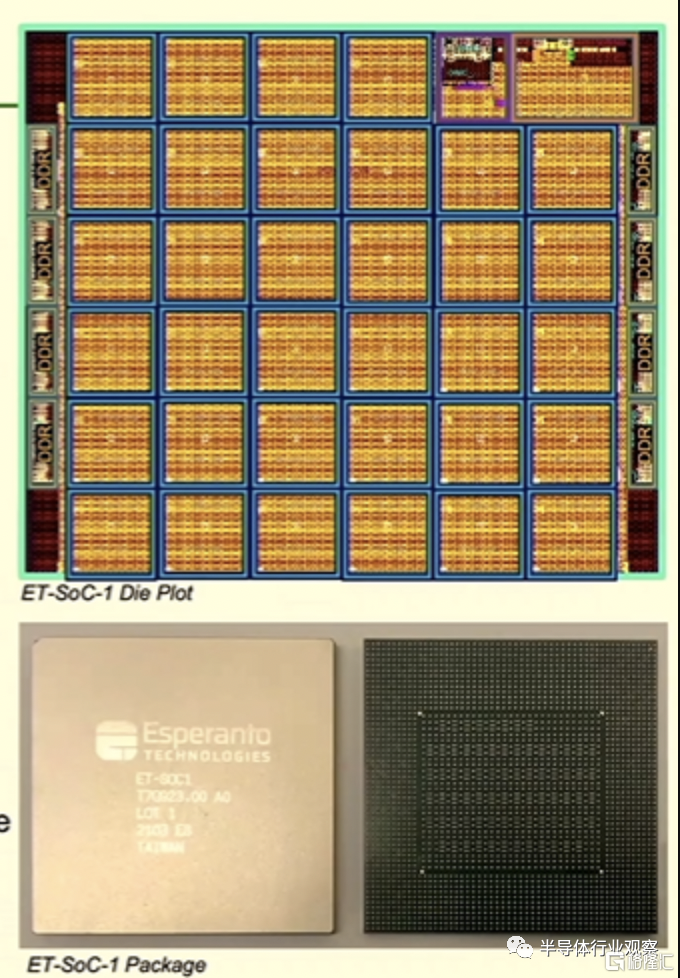
最重要的是,该芯片可以驱动 100 到 200 TOPS 的峰值速率并以低于 20 瓦的功率运行,这意味着其中 6 个芯片将低于 120 瓦的功率预算。
不同于其他的加速卡解决方案,一个巨大的热芯片就用尽了加速卡的整个功率预算。Esperanto 的方法是使用多个仍符合功率预算的低功率芯片,随着更多芯片的加入,性能提高、内存容量增加、内存带宽增加,低功耗和低成本的 DRAM 解决方案成为实用的解决方案。而RISC-V极简的指令集架构和逻辑门极少的特点还有助于对电路和架构的更改。
由于 ET-Minion Tensor 内核在最低电压和 8.5 瓦下运行,Esperanto 能够在远低于 120 瓦限制的情况下将 6 个芯片安装到加速卡中,比单个 118 瓦芯片解决方案提高 2.5 倍的性能功率效率比 275 瓦点高 20 倍。
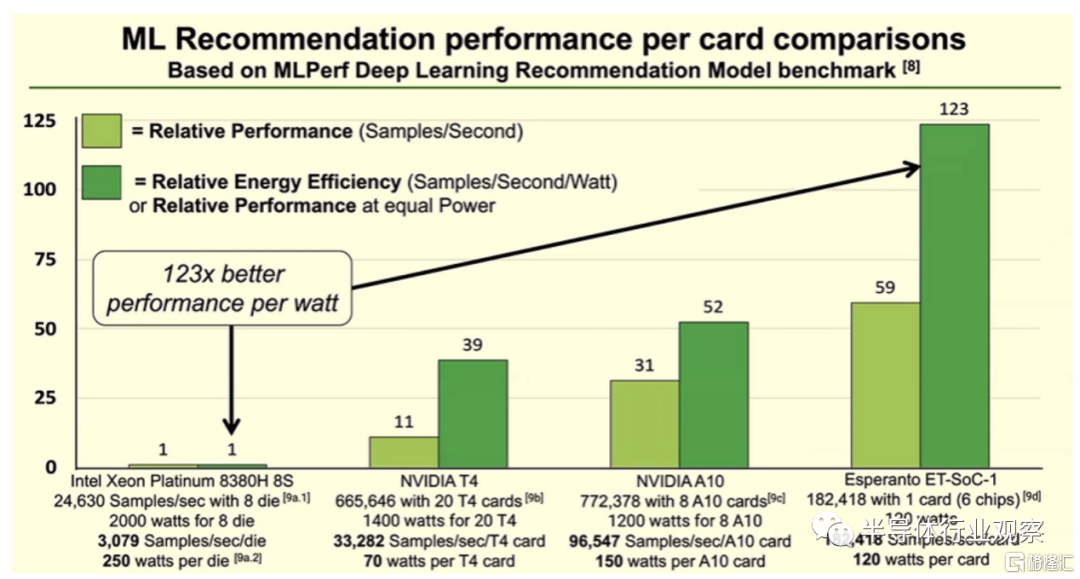
看向最终的性能,在使用MLPerf 深度学习推荐模型与英特尔的八路 Xeon Platinum 8380H 服务器处理器以及 Nvidia 的 A10 和 T4 GPU 的比较中发现,如下所示,Esperanto 芯片的性能是英特尔处理器的 59 倍,是每瓦性能的123倍,并且优于两个英伟达 GPU。据 Ditzel 称,类似的结果来自使用 ResNet-50 推理基准。
GPU也有戏?
RISC-V能处理GPU的事务吗?现在,研究人员研究了一种在名为 Vortex的RISC-V GPGPU 项目上启用 CUDA 软件工具包支持的方法。Vortex RISC-V GPGPU 旨在提供基于 RV32IMF ISA 的全系统 RISC-V GPU。这意味着 32 位内核可以从 1 核扩展到 32 核 GPU 设计。它支持 OpenCL 1.2 图形 API,还支持一些 CUDA 操作。
Nvidia 的 CUDA(计算统一设备架构)代表了一个独特的计算平台和应用程序编程接口 (API),它运行在 Nvidia 的显卡系列上。当为 CUDA 支持编写应用程序时,只要系统发现基于 CUDA 的 GPU,它就会获得大量的代码 GPU 加速。
研究人员解释说:“在这个项目中,我们提出并构建了一个pipeline来支持端到端的 CUDA 迁移:pipeline接受 CUDA 源代码作为输入并在扩展的 RISC-V GPU 架构上执行它们。我们的pipeline包括几个步骤:将CUDA源代码翻译成NVVM IR,将NVVM IR转换成SPIR-V IR,将SPIR-V IR转发成POCL得到RISC-V二进制文件,最后在扩展的RISC-V GPU上执行二进制文件架构。”
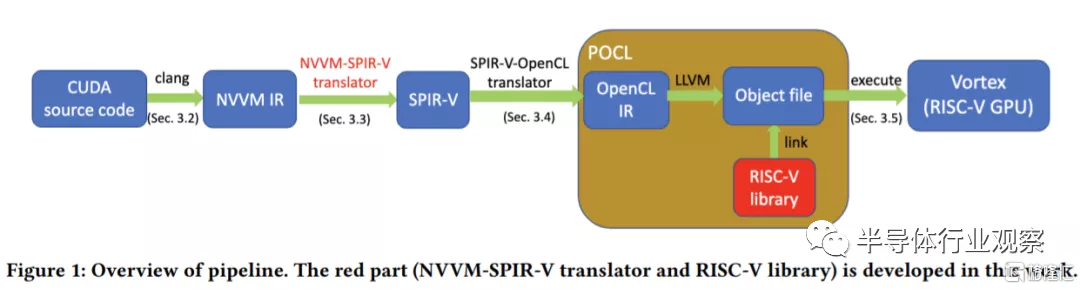
虽然CUDA能够在RISC-V GPGPU上运行只是一小步,但这可能是 RISC-V 用于加速计算应用程序时代的开始,这与 Nvidia 今天的 GPU阵容非常相似。
结语
综上来看,RISC-V的更多应用正在被一些初创的企业在探索,RISC-V全面开花的局面或许正在来临。



