 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
配对交易基础:关联,协整和配对交易被认为是最受欢迎的交易策略之一。
在这种策略中,通常以市场中立策略买卖一对股票,即,市场是向上还是向下都没关系,每个股票的两个未平仓头寸彼此对冲。配对交易策略的主要挑战是以下两点。
1. 选择一对将随着时间的推移为您提供良好的统计套利机会的货币对2. 选择入场时机/出场时机
在关于配对交易的这篇文章中,我们将涵盖以下主题:1. 相关性2. 协整
3. 如何选择股票进行配对交易?4. 什么是z分数?5. 定义入场位6. 定义出场位
7. Excel中的简单配对交易策略8. 交易模型的阐述以及细化
统计数据在决定交易对的第一个挑战中起着至关重要的作用。 通常从同一篮子股票中选择货币对,例如Microsoft和Google(技术领域)或ICICI&Axis(印度银行业)或Nifty Index和MSCI Index(市场指数)。在每个域中,可能有成千上万对。最好的是那些基于数学或统计测试的。我们将在配对交易的下一部分中学习两种统计方法。
相关性尽管不常见,但一些对交易策略着眼于相关性以找到合适的交易对。相关性由相关系数ρ量化,相关系数ρ介于-1至+1之间。相关系数表示两个变量之间的相关程度。+1的值表示两个变量之间存在完美的正相关,-1的值表示存在完美的负相关,0表示没有相关。
理想的正相关模式是当一个变量沿向上或向下方向移动时,另一个变量也沿相同的方向以相同的幅度移动,而理想的负相关是当一个变量沿向上方向移动时,另一个变量沿相同方向移动。向下(即相反)方向,幅度相同。
两个变量的相关系数由Correlation(X,Y)=ρ= COV(X,Y)/ SD(X).SD(Y)给出,其中cov(X,Y)是X& Y,而SD(X)和SD(Y)表示各个变量的标准偏差。
如果相关性很高,例如0.8,交易者可以选择该对进行交易。 这个高数字代表着两只股票之间的牢固关系。因此,如果A上升,则B上升的机会也很高。基于此假设,在购买A和出售B的情况下,采取市场中立策略。购买和出售的决策是根据其各自的模式而做出的。
仅查看相关性可能会给带来虚假的结果。例如,如果配对交易策略基于两个股票价格之间的价差,那么两个股票的价格可能会持续上涨,而不会发生均值回复。
Spread = log(a)– nlog(b),其中“ a”和“ b”分别是股票A和B的价格。买入A的每只股票,你卖出了n份B的股票。现在,“ a”和“ b”都以使价差值减小的方式增加。这将导致亏损,因为股票A的增长速度低于股票B的增长,并且你手上的股票B将出现短缺。
因此,应该谨慎地只将此策略用于配对交易。
现在让我们进入成对交易基础,即关于协整的下一部分。货币对交易最常见的测试是协整测试。协整是两个或多个时间序列变量的统计属性,它指示变量的线性组合是否平稳。让我们了解上面的陈述。在这种情况下,两个时间序列变量是股票A和B的价格的对数。
这些变量的线性组合可以是定义点差的线性方程式:如我们所知,Spread = log(a)– nlog(b),其中“ a”和“ b”分别是股票A和B的价格。对于购买的每只A股票,你将卖出对应n股B股票。如果A和B是协积分的,则意味着上面的方程是平稳的。固定过程具有非常有价值的特征,这些特征是对交易策略建模所必需的。例如,在这种情况下,如果上面的方程式是固定的,则表明该方程式的均值和方差随时间保持恒定。因此,如果我们从“ n”开始,这被称为对冲比率,那么利差= 0,平稳的属性意味着利差的期望值将保持为0。任何偏离该期望值的情况都是统计异常。
牢记这一理论,让我们尝试在配对交易基础知识的下一部分中回答可能会想到的问题。
如何选择股票进行配对交易?对于任何一对股票,定义点差如下:Spread = log(a)– nlog(b),其中“ a”和“ b”分别是股票A和B的价格。假设:n,套期比率是恒定的。使用回归计算“ n”,以使传播范围尽可能接近0。因此,我们对股票价格进行回归计算对冲比率。理论:在回归中,我们得到一个称为残差的术语,它表示观测值与曲线拟合线或估计值的距离。这些残差告诉我们,对于计算出的“ n”,“ spread”的实际值与0的偏差是多少。对这些残差进行了研究,以便我们了解它们是否形成趋势。如果它们没有形成趋势,则表示价差将随机在0附近移动并保持稳定。在传播值上插入“ n”值的值上运行Dicky Fuller测试(更复杂和流行的版本称为Augmented Dicky Fuller Test或ADF)。Dickey Fuller检验是一种假设检验,给出pValue作为结果。如果该值小于0.05或0.01,则可以以95%或99%的置信度说信号是平稳的,我们可以选择此对。到目前为止,我们已经讨论了选择一对股票进行统计套利所涉及的挑战和统计数据。我们了解到,通过使用协整检验,我们可以说在一定的置信区间内,两只股票之间的价差是一个平稳的信号。
换句话说,该信号是均值回复的。
点差定义为:Spread = log(a)– nlog(b),其中“ a”和“ b”分别是股票A和B的价格。对于购买的每只A股票,您已经卖出了n股B股票。n是通过对A和B股票价格进行回归计算得出的。已经确定上述方程式为均值回归后,我们现在需要确定极限点或阈值水平,当达到该信号时,我们将触发交易对进行交易对。为了能够识别这些阈值水平,在配对交易中广泛使用了称为z得分的统计结构。在下一部分中,我们还将与z得分一起简要介绍移动平均线,这是配对交易的另一个重要组成部分。什么是z分数?简而言之,在给定原始数据点的正态分布的情况下,将计算z分数,以使新分布为均值0和标准偏差为1的正态分布。拥有〜N(0,1)的分布对于创建阈值水平非常有用。例如,在成对交易中,我们在股票A和B的价格之间分配了点差。我们可以将这些点差的原始分数转换为z分数,如下所述。此新分布的平均值为0,标准偏差为1。很容易为此分布创建阈值级别,例如1.5 sigma,2 sigma,2.5 sigma等。如何计算z分数?z =(x –平均值)/标准差,其中x是原始数据点,z是z分数。平均值和标准差可以是“ t”天或几分钟或时间间隔内的滚动统计。
移动平均线(moving average)我们将数据分成大小为“ t”的子集,其中“ t”指定了要计算平均值的固定时间段。例如,要计算“ t”为10天的股票A的价格移动平均值,我们首先要计算数据集中前10天之后的平均值。因此,我们在第10天,11天,12天等计算移动平均线。平均值在移动或滚动。下表针对10天计算了移动平均线和标准差,即“ t”。2001年1月8日或第11个条目的移动平均线不会考虑第一个数据点,即2001年7月18日的A股票价格。使用移动平均线和z分数的这些概念,我们创建配对交易的入口点。定义入场点让我们将Spread表示为s。因此,Spread = s = log(a)– nlog(b)使用滚动平均值和标准偏差在“ t”时间间隔内计算“ s”的z得分。将此另存为z。将阈值定义为1.5-sigma,2-sigma。该参数将根据回测结果进行更改,而不会冒数据过度拟合的风险。当Z得分超过上限时,请可以卖空:卖出股票A购买股票B当z得分超过下限阈值时,可以做多:购买股票A卖出股票B保持对冲比率以计算库存数量我们现在已经了解了配对交易中的切入点。现在,我们将移至另一端,即退出点。定义出场点如何止损对于未发生预期的情况,定义了止损。例如,如果我们选择2-sigma的进入信号,那么我们期望价差将从该阈值恢复为均值。但是,传播可能继续膨胀。假设它达到2.5-sigma,您就蒙受了损失。为了防止进一步的损失,您将止损设置为3σ。除了放置预定义的止损标准(例如3-sigma或均值的极大变化)之外,您还可以检查协整值。如果在货币对为ON期间破坏了协整,则该策略值得削减头寸,因为基本假设无效。从套利策略获利它被定义为在价格朝另一个方向移动之前您获利的情况。例如,假设对价差很长,也就是说,根据商品中价差的定义,带来了库存A,出售了库存B。期望价差将恢复为均值或0。在有利的情况下,均值将接近零或非常接近均值。从均值阈值水平恢复后,当均值首次过零时,可以保持止盈方案。根据自身风险偏好和回测结果,可以有很多定义获利的方法。让我们尝试回顾到目前为止我们已经了解的内容。交易对是一种交易策略,该策略将一只股票/资产中的多头头寸与另一只具有统计意义的股票/资产中的抵消头寸相匹配。配对交易可以称为均值回归策略,在此我们押注价格将恢复其历史趋势。
到目前为止,我们已经研究了配对逃离的概念,现在让我们尝试利用excel创建一个相对简单的配对套利策略,此Excel模型将帮助您:1. 了解均值回归的应用2. 了解配对交易3. 优化交易参数
4. 了解统计套利的重大收益为什么要下载交易模型?由于交易逻辑在工作表的单元格中进行了编码,因此您可以通过方便的方式下载和分析文件来提高理解度。不仅如此,您还可以四处摸索以获得更好的结果。您可能会找到合适的参数,这些参数提供比文章中指定的更高的利润。模型说明在此示例中,我们将MSCI和Nifty对视为股票指数,因为它们都是股票指数。我们在这对上实施均值回归策略。均值回归是固定时间序列的属性。因为我们声称我们选择的那对是平均反转,所以我们应该测试它是否遵循平稳性。绘制Nifty与MSCI的对数比使其看起来像是均值回复,平均值为2.088,但是我们使用Dicky Fuller检验来检验它是否平稳,具有统计学意义。协整输出表下的结果表明价格序列是固定的,因此均值回复。Dicky Fuller测试统计量和显着较低的p值(<0.05)证实了我们的假设。在确定均值回归对所选对而言正确之后,我们继续指定假设和输入参数。假设条件为了简化起见,我们忽略了买卖差价,价格间隔为5分钟,我们仅以5分钟收盘价交易。由于这是离散数据,所以在蜡烛的末尾(即在5分钟末可用的价格)进行仓位平方。
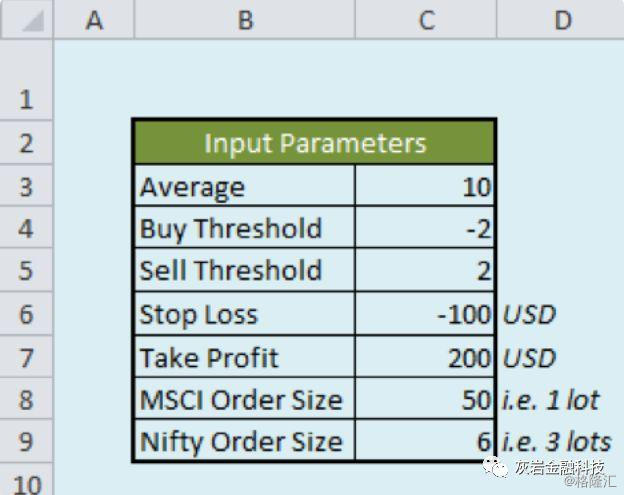
仅常规时段(T)被交易Nifty的交易成本为0.375美元,MSCI的交易成本为1.10美元。每笔交易的保证金为990美元(约合1000美元)。输入参数:请注意,下面提到的输入参数的所有值都是可配置的。平均10支蜡烛(一根蜡烛等于每5分钟的价格)购买时考虑“ z”得分+2,出售时考虑“ -2”得分
设定了100美元的止损和200美元的利润限额,交易MSCI的订单大小为50(1手),Nifty的订单大小为6(3手)从第12行开始,电子表格中包含市场数据和交易参数。因此,当引用D列时,显然应该从D12开始引用。
Excel模型中各列的说明
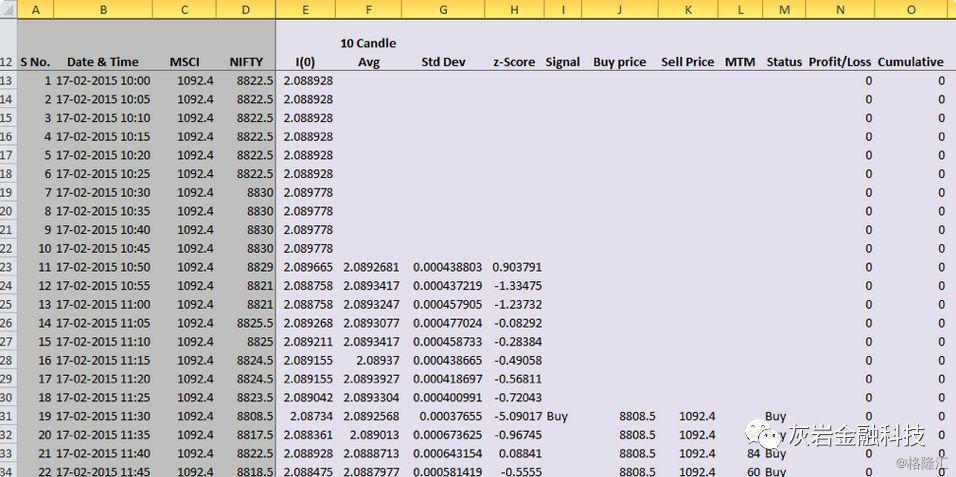
C列表示MSCI的价格。
D列代表漂亮的价格。E列是Nifty与MSCI的对数比。F列计算10根蜡烛平均值。
由于平均计算需要10个值,因此从F12到F22没有值。公式= IF(A23> $ C $ 3,AVERAGE(INDEX($ E $ 13:$ E $ 1358,A23- $ C $ 3):E22),“”)表示仅当可用数据样本为大于10(即,单元格C3中指定的值),否则该单元格应为空白。考虑单元格F22。其对应的单元格A22的值为10。由于A22> $ C $ 3失败,因此该单元格中的条目为空。下一个单元格F23具有值,因为A23> $ C $ 3为真。让我们移至下一列。在G列中,公式AVERAGE(INDEX($ E $ 13:$ E $ 1358,A23- $ C $ 3):E22)计算E列数据的最后10个蜡烛的平均值(如单元格C3中所述)。对于计算标准偏差的G列,也具有类似的逻辑。在列H中计算“ z”分数。用于计算“ z”分数的公式是z =(x-μ)/(σ)。x是样本(E列),μ是平均值(F列),σ是标准偏差(G列)。第一列代表交易信号。如输入参数中所述,如果“ z”得分低于-2,我们购买,如果得分高于+2,我们出售。当我们说买入时,我们在3手Nifty中有多头头寸,而在1手MSCI中有空头头寸。同样,当我们说卖出时,我们在1手MSCI中有多头头寸,而在3手Nifty中有空头头寸,因此平仓。我们一直都有一个空缺职位。要了解这意味着什么,请考虑两个交易信号“买入”和“卖出”。如前所述,对于“买入”信号,我们买入3手Nifty期货和空头1手MSCI期货。取得头寸后,我们将使用“状态”列(即列M)来跟踪头寸。在头寸继续的每个新行中,我们检查止损(如单元格C6中所述)或获利(如单元格中所述) C7)被击中。在单元格C6和C7中,给定止损值-100美元,即损失100美元,获利了结200美元。尽管头寸既未达到止损或止盈,我们仍继续进行该交易,并忽略了第一列中出现的所有信号。一旦交易达到止损或获利,我们再次开始查看列中的信号在第I列中出现“买入或卖出”信号后,我立即开立新的交易头寸。列M表示基于指定输入参数的交易信号。第一栏已经有交易信号,M告诉我们交易头寸的状态,即我们是做多还是做空或预定利润或以止损退出。如果未退出交易,则通过重复前一个蜡烛中的状态栏的值,将头寸转到下一蜡烛。如果价格走势以违反给定目标价或目标价的方式发生,那么我们调整仓位,分别用“目标价”和“ SL”表示。L列表示按市价计价。它指定时间段结束时的投资组合头寸。如输入参数中所指定,我们交易1手MSCI和3手Nifty。因此,当我们交易时,头寸是适当的价格差(取决于我们是否买卖)乘以手数。N栏代表交易的盈亏状况。仅当我们平掉头寸后才计算盈亏。
O列计算累计利润。
结论输出表中列出了一些性能指标。来自所有亏损交易的亏损为3699美元,达到目标价的交易的利润为9280美元。因此总P / L为$ 9280- $ 3699 = $ 5581。亏损交易是导致交易头寸亏损的交易。获利交易是指以获利为目的的成功交易。平均利润是总利润与总交易次数的比率。扣除交易费用91.77美元后,计算出平均净利润。摘要因此,我们了解了配对交易策略(包括关联和协整)背后的概念。我们还研究了Z分数,并在执行配对交易策略时定义了进入点和退出点。我们还为配对交易策略创建了一个Excel模型。



