 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
4月18日,Meta公司推出其开源大语言模型“Llama”(直译是“羊驼”)系列的最新产品——Llama 3。此次发布共发布乐两款开源Llama 3 8B与Llama 3 70B模型,供外部开发者免费使用。Llama 3的这两个版本,也将很快登陆主要的云供应商。
根据Meta的说法,Llama 3 8B和Llama 3 70B是目前同体量下,性能最好的开源模型。强大的性能离不开庞大的训练数据。据Meta透露,Llama 3是在由24000块GPU组成的定制集群上,使用15万亿个token训练的,数据规模几乎是Llama 2的七倍。
Llama 3的推出,对开发者社区意义重大。Hugging Face联创兼CEO Clément Delangue表示:“Llama 1和Llama 2现在已经衍生出了30,000个新模型。我迫不及待地想看到Llama 3将会给AI生态带来怎样的冲击了。”
具体来说,Llama 3的主要亮点有:
• 在大量重要基准测试中均具有最先进性能;
• 基于超过15T token训练,大小相当于Llama 2数据集的7倍还多;
• 训练效率比Llama 2高3倍;
• 安全性有明显进步,配备了Llama Guard 2、Code Shield等新一代的安全工具。
/ 01 /性能全面领先的Llama 3
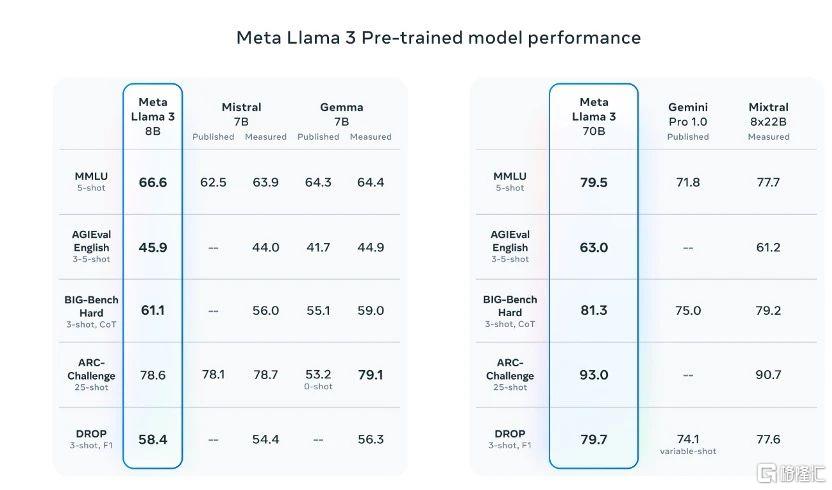
从发布的信息看,Llama 3公布了10项标准测试基准的表现,其中在与70亿参数级的Mistral 7B模型和Google Gemma 7B模型对比中,Llama 3在9项标准测试基准上都有着更好的表现。
其中,包括MMLU(测试知识水平)、ARC(测试技能获取)、DROP(测试对文本块的推理能力)、GPQA(涉及生物、物理和化学的问题)、HumanEval(代码生成测试)、GSM-8K(数学应用问题)、MATH(数学基准)、AGIEval(问题解决测试集)和BIG-Bench Hard(常识推理评估)。
从上图不难看出,Llama 3 8B的成绩在九项测试中领先同行,其中Gemma-7B模型于今年2月发布,一度被称为全球最强开源大模型。Llama 3 70B则在MMLU、HumanEval和GSM-8K上战胜了Gemini 1.5 Pro,同时在五项测试上全面优于Claude 3系列的中杯模型Sonnet。

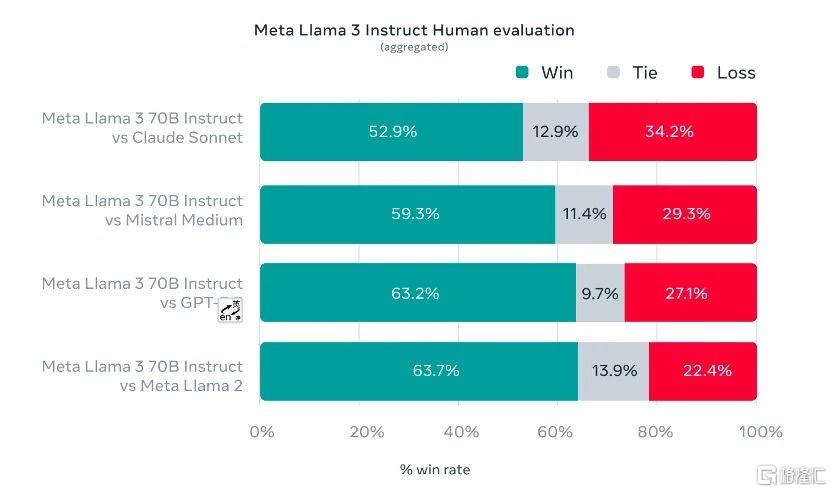
值得一提的是,Meta还组织了一个贴近用户实际使用体验的测试。根据Meta的说法,该测试集包含 1,800 个提示,涵盖 12 个关键场景:寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作、提取、塑造角色/角色、开放式问答、推理、重写和总结。
测试数据显示,70B 版本的 Llama 3 在指令调优后,在对比 Claude Sonnet、Mistral Medium、GPT-3.5 和 Llama 2 的比赛中,其胜率分别达到了 52.9%、59.3%、63.2%、63.7%
Llama 3一经发布便引发了热议。埃隆·马斯克在杨立昆的X下面评论:“还不错。”英伟达高级研究经理、具身智能负责人Jim Fan认为,即将推出的Llama 3-400B+模型将成为社区获得GPT-4级别模型的重要里程碑。它将改变许多研究工作和草根初创公司的计算方式。
据Meta披露,Llama 3即将在亚马逊云(AWS)、Databricks、谷歌云、Hugging Face、Kaggle、IBM WatsonX、微软云Azure、NVIDIA NIM和Snowflake等多个平台上推出。这一过程得到了AMD、AWS、戴尔、英特尔和英伟达等公司的硬件支持。
近期,Meta也将计划推出Llama 3的新功能,包括更长的上下文窗口和更强大的性能,并将推出新的模型尺寸版本和公开Llama 3的研究论文。
/ 02 /最强开源模型怎样炼成?
Llama 3优越的性能,离不开Meta在训练数据上的投入。根据Meta透露,Llama 3训练数据规模高达15 万亿token,几乎是Llama 2的七倍。
不仅如此,为了满足多语种的需求,Llama 3超过 5%的预训练数据集,由涵盖 30 多种语言的高质量非英语数据组成。
为了确保 Llama 3 接受最高质量数据的训练,Meta还开发、使用了启发式过滤器、NSFW 过滤器、语义重复数据删除方法和文本分类器来保证数据质量。
相比数据规模,数据来源更加令人关注。毕竟,此前Meta因训练数据不足而产生焦虑,甚至一度爆出消息,在最近的一次高层管理会议中,Meta高管甚至还建议收购出版社 Simon & Schuster以采购包括史蒂芬金等知名作家作品在内的长篇小说为其AI模型提供训练数据。
在此次发布Llama 3中,对于数据来源,Meta只说了“收集于公开来源”。不过根据外媒的说法,Llama 3使用的训练数据,有很大一部分是AI合成的数据。有趣的是,两个版本的数据库日期还略微有点不同,8B版本截止日期为2023年3月,70B版本为2023年12月。
除了提高数据规模和质量外,Meta花了很多精力在优化训练效率上,比如数据并行化、模型并行化和管道并行化。当16000个GPU集群上进行训练时,Meta最高可实现每个GPU超过 400 TFLOPS的计算利用率。
同时,为了延长 GPU 的正常运行时间,Meta开发了一种先进的新训练堆栈,可以自动执行错误检测、处理和维护。
此外,Meta还极大地改进了硬件可靠性和静默数据损坏检测机制,并且开发了新的可扩展存储系统,以减少检查点和回滚的开销。这些改进使总体有效培训时间超过 95%。综合起来,这些改进使Llama 3的训练效率比Llama 2提高了约三倍。
为了优化Llama 3的聊天和编码等使用场景,Meta 创新了其指令微调方法,结合了监督微调、拒绝采样、近似策略优化和直接策略优化等技术。这些技术不仅提升了模型在复杂任务中的表现,还帮助模型在面对难解的推理问题时能生成正确的解答路径。
在外界关注的安全性上,Meta采用了一种新的系统级方法来负责任地开发和部署Llama 3。他们将Llama 3视为更广泛系统的一部分,让开发人员能够完全掌握模型的主导权。
指令微调在确保模型的安全性方面也发挥着重要作用。Meta的指令微调模型已经通过内部和外部的努力进行了安全红队(测试)。Meta的红队方法利用人类专家和自动化方法来生成对抗性提示,试图引发有问题的响应。比如,他们进行了全面的测试,来评估与化学、生物、网络安全和其他风险领域相关的滥用风险。
通过以上的种种努力,才最终打造了最强开源大模型Llama 3。据国外媒体道理,Meta希望Llama3能赶上OpenAI的GPT-4。
由此可见,开源和闭源的争论远远没有到停下的时候。如今,Meta用Llama 3给出自己的回应,接下来就看OpenAI如何应对了?



