 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
作者:李飞
来源:半导体行业观察
近日,Intel宣布了在AI领域的一个新动作:新近收购的Habana的系列产品将取代原定的服务器端AI加速芯片Nervana Spring Crest NNP-T,而Spring Crest NNP-T系列将停止开发。本文将对Intel的这个决定做深入解读。
Intel收购Nervana:Intel在AI领域的第一个大动作
我们首先分析一下Nervana Spring Crest系列产品的由来。为此,我们需要先介绍一下Nervana Systems这家三年前被Intel收购的公司。
Nervana Systems成立于2014年,是一家在AI尚未真正成为风口时就宣布做AI底层架构的初创公司,其投资人包括DCVC、Lux等顶级硅谷风投。2015年,Nervana在深度学习领域发布了其主要产品,即深度学习底层框架Neon。Neon是一个为深度学习仔细优化的底层框架,在算子层级拥有很高的效率。Neon最初是运行在Nvidia GPU上,然而其性能比起Nvidia的亲儿子CuDNN都要强不少。2015年正是Caffe等深度学习框架火热的时候,而Neon凭借其卓越的性能自然获得了大家的关注。
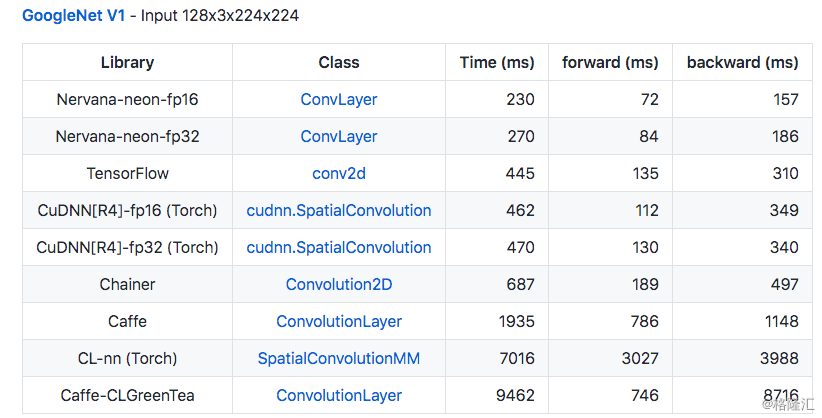
在凭借Neon一炮而红后,Nervana在2016年初宣布了其更加野心勃勃的计划,即Nervana Cloud。在Nervana Cloud中,Nervana将会把Neon框架运行在其为Neon专门优化的Nervana Engine芯片上。Nervana宣布这样的组合将会实现10倍于Nvidia Titan X的性能。可以说,在大多数半导体公司对于AI还持观望态度的2016年初,Nervana宣布这样大计划可谓是站在了时代的前沿。而且,Nervana对于市场的判断非常准确:因为就在不久之后,AI芯片就成为了为整个行业公认的风口,而Nervana也在2016年下半年被Intel以4亿美元收购。在收购的时候,Nervana并没有发布任何芯片细节:我们可以估计在收购时,大概率Nervana还只有一个芯片架构设计,并没有真正的芯片原型,更没有芯片产品。
在Nervana被Intel收购之后,其产品也逐渐融入Intel的产品路线图。然而,Nervana预想中的Nervana Engine进度并不顺利。在被收购后,Nervana Engine重新定名为Crest系列。2017年初,Intel发布了Nervana Lake Crest的一些细节,并且宣布2017年上半年将会有芯片成品。到了2018年中,Intel宣布Lake Crest只是一个试用版的原型产品,而正式的芯片产品命名为Spring Crest,将会于2019年正式发售。在那个时候,Lake Crest的性能指标为12核,32GB HBM内存,峰值算力为38TOP/s。在2019年八月的Hot Chips,Intel又发布了Nervana芯片的相关更新:Nervana将发售两种芯片,一种是针对服务器端训练应用的Spring Crest NNP-T,它将具有119TOPS的峰值算力,并且通过CoWoS高级封装技术实现多芯片互联;而另一款则是针对边缘计算的Spring Hill NNP-I,功耗10W,能效比为4.6TOPS/W。然而,在2019年我们并未得到Spring Crest系列真正商用的消息,直到最近才得到它已经被取消的新闻。
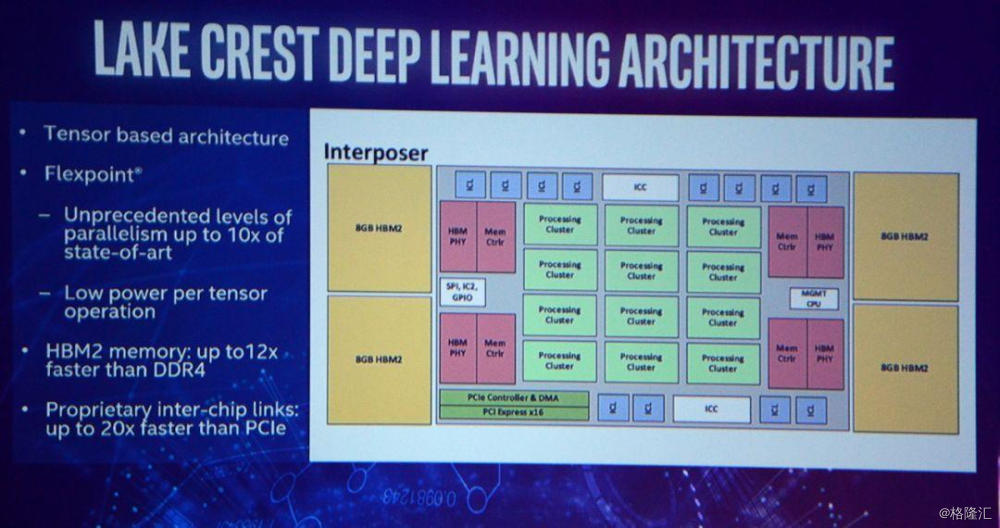
Intel在2017年发布的Nervana Lake Crest架构,拥有Tensor-based architecture、Flexpoint、Silicon Interposer等多个热门词汇
靠谱的Habana
相比产品迟迟不能量产的Nervana,来自以色列的初创公司Habana可以说是实在也靠谱多了。
Habana的芯片分为两个系列,即针对训练的Gaudi系列和针对推理的Goya系列。与Nervana最大的不同在于,Habana的两个芯片系列目前都已经有成品芯片供客户使用,目前据悉已经收获了一些数据中心客户的青睐。
Habana的芯片架构可以用“实在”来概括。其架构并没有用许多花哨的概念性技术——在技术白皮书中,Habana直接明了地告诉大家其架构就是VLIW SIMD,一种广为人知的架构。
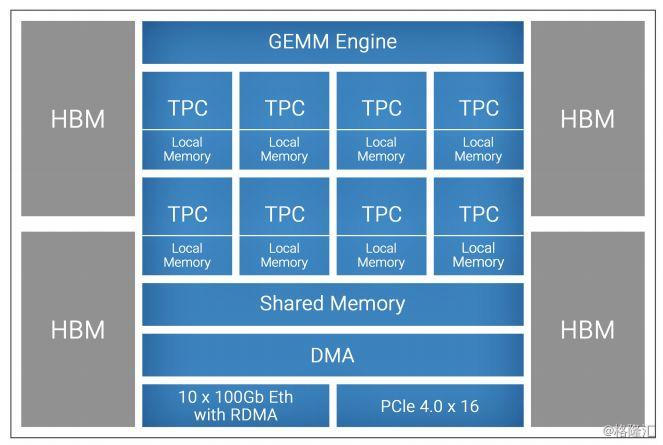
VLIW和SIMD技术早在上世纪就已经提出,到今天已经拥有超过20年的历史。其中,SIMD(单指令流多数据流)架构的核心是利用数据并行性,让处理器只需要一条指令就能处理大量并行数据,该技术早已或多或少地应用在高性能计算处理器中(例如GPU使用的SIMT技术可以认为是SIMD技术的一种衍生)。SIMD对于存在大量数据并行的深度学习来说非常合适,这也是Habana在其深度学习加速芯片中使用SIMD的主要原因。
VLIW技术(超长指令字)则是另一个用于并行计算的重要技术,其核心是让编译器去找出在一个指令中能并行执行并充分利用处理器资源的多个计算操作。在通用计算时代,VLIW曾遭遇了一次失败(本世纪初的Intel的Itanium系列),因为在通用计算时代程序中会有大量的分支判断,从而造成静态编译器难以预测可以并行操作的指令,造成性能损失。然而,VLIW并未被人抛弃,在20年间VLIW在DSP等计算较为规整的应用领域获得了一席之地,直到今天深度学习时代又重现江湖。在深度学习应用中,计算很规整,因此编译器可以很好地预测操作并行性并作相应调度。而一旦使用VLIW,则用于深度学习加速的处理器可以省去传统超标量处理器中复杂的片上硬件调度模块,从而可以把芯片面积留给真正用于计算的单元。
可以说Habana使用了两个广为人知(但是非常适合深度学习)的技术实打实地把芯片做了出来,并且在工程上把细节做到了完美。事实上,我们认为Habana芯片的工程量并不小,尤其是在硬件之外的软件编译器部分——因为VLIW需要一个非常高效的编译器才能保证其性能,即使是在计算较规整的深度学习应用,做好这样的编译器也并不容易。
基于其扎实的产品,Habana已经开始了与多个云端数据中心客户的合作,并且于去年底被Intel收购。
Intel需要什么样的AI芯片产品
对于Intel来说,在错过了移动计算之后,人工智能时代不能再错过了。目前来看,Intel在人工智能领域的终端计算(收购Movidius)、边缘计算和云端计算都有布局,但是重中之重还是利用Intel一直以来在云数据中心的强势地位来确保打下云计算人工智能芯片市场。这也是它接连收购Nervana和Habana这两家云端人工智能芯片公司原因。
那么,Intel究竟需要什么样的芯片产品呢?首先,Intel需要一个能按时交付不跳票的产品。在这个时间点上,云端人工智能芯片在几年内成为数据中心的刚需已成定局,如果Intel没法在近期打破Nvidia的垄断真正打入云端人工智能芯片市场,那么未来想要打入会越来越困难。更关键的是,目前云数据中心的几大巨头都在自己布局芯片,例如Google已经有了TPU,Amazon、阿里巴巴自研的深度学习加速芯片也已经流片完成,腾讯也投资了本土的GPU初创公司燧原,因此如果等到几年后云数据中心都开始使用自研芯片的时候,Intel就更难打入这个市场了。这也是Intel使用已经有产品的Habana替代迟迟不能交付的Nervana最关键的原因。
其次,从技术上来说,云端芯片最关键的门槛在于可扩展性,即如何能保证云端芯片在大规模部署(包括一机多卡,多机等情形)的时候,其总体性能可以保持接近线性增长。可扩展性门槛高的原因是它是一个系统工程,并非是把单芯片性能做好就行了——要做到可扩展性,需要在设计芯片的同时就考虑其与其他芯片通信的能力,同时需要在软件上也给予大量的支持才能让整个系统的性能充分发挥。这事实上需要非常高的工程量,同时也需要团队能对于整个分布式系统有深入的理解才能把系统做好。我们看到,Habana在这方面交出了令人满意的答卷:Habana的芯片上自带RDMA模组,因此可以支持大规模的分布式计算;另外,在设计底层编译器和软件架构的时候也充分考虑了软硬件协同系统设计,因此Habana的可扩展性非常好。根据官方公布的数字,其分布式总体性能甚至在处理器数量大于600的时候也能接近线性,从而比起同样处理器数量的Nvidia V100 GPU,其训练性能提高了接近4倍,这是一个非常了不起的结果,其中必定包含了大量芯片和软件/算法工程师的努力。

综合以上的分析,我们认为Intel用Habana Gaudi系列产品代替原计划中的Nervana Spring Crest可以概括为是“高质量系统工程的胜利”。之后Intel在云端人工智能芯片领域能否真正打开市场,让我们拭目以待。



