 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
作者: 童淑婷
来源:刺猬公社(ID:ciweigongshe)
算法分发是未来之物,它是信息过载时代智能分发的产物;算法分发或也终将成为过去之物,因为下一代技术的发展永远可以突破当代人的想象,就像宋朝人无法想象移动互联网。
算法分发、编辑分发、社交分发……在信息时代,人们常常讨论信息分发问题,相关概念也成为大热名词。
但事实上,信息资源一直在人类的进化和发展中占据着重要位置。社交分发是最古老的分发方式,编辑分发也比我们想象得更早。
而当我们把算法分发置于人类社会信息分发的历史长河中,便能清楚地看到它的“前”与“后”——从这个角度来看,新鲜的算法推荐,其实也不新鲜。
亘古的信息分发问题
信息分发,是一个亘古问题。
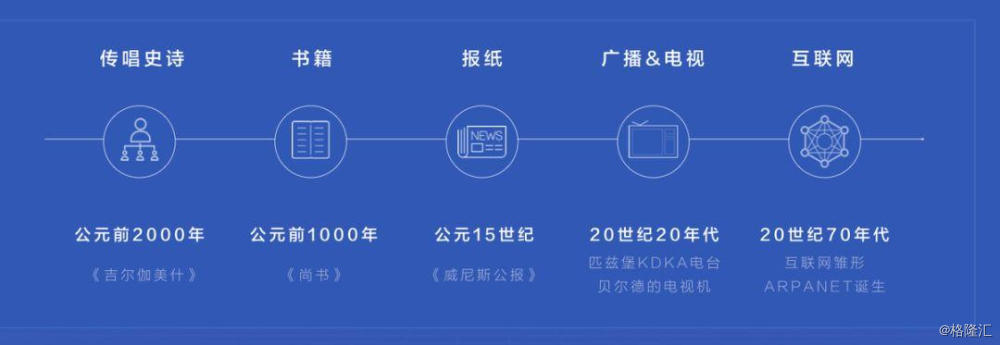
不妨从一个有趣的联想开始:在人类文明早期,群居的祖先们依靠采集和狩猎生存。由于狩猎是一个非常危险的技术活,人们需要交流狩猎作战的信息和经验,来提高成功率。
比如,猎物出现时用什么信号召集同伴?从什么位置伏击猛兽效果更好?他们通过手势和发声,把这些重要信息分发给同伴——这便是“社交分发”,人类社会最原始的信息分发方式。
“知”(甲骨文):
 甲骨文的“知”就表示谈论和传授行猎、作战的经验。
甲骨文的“知”就表示谈论和传授行猎、作战的经验。
社交分发的意思是基于社交关系的直接和自然的分发。《人类简史》用“八卦”来描述这种信息交流,指出八卦对人类进化的重要作用。
另一种自古就有的信息分发形式,则是编辑分发。虽然英文“edit”一词的出现和报纸相关,可这种分发形式早已有之。
在口传时代,由古希腊盲诗人荷马搜集、整理而成的“荷马史诗”(《伊利亚特》和《奥德赛》)就是典型例子。汉语将“编辑”解释为“收集资料,整理成书”。去其形,取其义,这种信息分发的根本特征是:信息经过整理后分发至接受者,有加工和把关的意涵。
无论社交分发,还是编辑分发,它们都已经历史悠久。只是承载这些分发方式的具体媒介在不断更新和变化,也给这些分发方式带来了新的可能。
比如,互联网通过对社交关系的限制(地域、血缘等)突破,在某种程度上实现了跨区域的社交联结,也让社交分发的范围从家庭、线下社区,转向更广的兴趣群体。

进入互联网时代,科学家和工程师都在努力解决信息过载环境下的分发问题,早期两种代表性的解决方案是分类目录和搜索引擎——前者,通过人工编辑把知名网站分门别类,让用户根据类别来查找网站,典型如雅虎、Hao123等;后者,让用户通过搜索关键词找到所需信息,解决了分类目录的有限覆盖问题,典型如谷歌、百度等。
实际上,这两种解决方案的思路并不新鲜,很大程度上可以分别对应图书馆的分类馆藏和百科全书的条目索引。
纵观整个历史长河,我们不难发现:信息环境是变化的,解决方案是具体的,但信息分发的需求和方式却是相通的。它们都在回答一个问题——如何有效地连接人和信息。
推荐算法:熟悉的新朋友
算法分发的出现和普遍应用,意味着人类开始运用机器大规模地解决信息分发问题,人类社会信息分发的动力从人力转向了部分自动化——从“人找信息”,到“信息找人”。
站在人类社会信息分发的长河中看,算法分发虽然是一个新鲜事物,但它的使命和根基却是熟悉的。从这个切口去思考,不难回答为什么这个时代诞生了推荐算法:
第一,新的信息环境和人类的信息需求动力,呼唤一种新的信息分发解决方案。
面对信息过载的环境和碎片化的信息消费场景,如何从大量信息中找到自己感兴趣的信息,是一件非常困难的事情。作为重要工具的搜索引擎,可以部分满足人们的需求,但最适用于需求明确的场景。如果用户无法准确描述自己的信息搜索需求,甚至对自己的需求都不充分了解呢?
这意味着,我们需要一个能够主动根据我们的兴趣和需求来分发信息的方案。早在1995年出版的《数字化生存》(Being Digital)中,尼古拉·尼葛洛庞帝便提出“我的日报”(The Daily Me),认为在线新闻将使受众主动选择自己感兴趣的内容,预言未来信息的个人化。
在当时,这种设想可能被认为是“白日做梦”。因为个体之间自然有差异,而为了社会的总体效率,人们总是尽可能寻找信息的“公约数”。
随着技术的发展,推荐系统的出现给人类的信息分发带来了一种可能:人们不用每次都提供明确的需求,而是通过为不同个体的信息需求建模,从而主动推荐能够满足他们兴趣和需求的信息。
第二,信息技术的发展,为个性化推荐系统的出现提供了物质条件。
一方面,移动互联网发展,每个人都是一个终端,这使得信息的分发能够低成本定位到不同的个体用户。
另一方面,AI技术的成熟和硬件资源的进化,为个性化推荐提供了技术实现路径:机器学习模型的应用,深度学习的快速发展等,提供了有力的算法工具;而大规模分布式机器学习框架的出现、GPU对深度学习的加速能力得到普遍验证、专用深度学习芯片的出现(TPU、寒武纪),又提供了另一层保障。
1994 年美国明尼苏达大学GroupLens研究组推出第一个自动化推荐系统 GroupLens(1),提出了将协同过滤作为推荐系统的重要技术,也是最早的自动化协同过滤推荐系统之一。
1998年亚马逊(Amazon.com)上线了基于物品的协同过滤算法,将推荐系统推向服务千万级用户和处理百万级商品的规模,并能产生质量良好的推荐。
2006 年10月,北美在线视频服务提供商 Netflix 开始举办著名的Netflix Prize推荐系统比赛。参赛者如能将其推荐算法的预测准确度提升10%,可获得100万美元奖金。参赛的研究人员提出了若干推荐算法,大大提高推荐准确度,极大地推动了推荐系统的发展。
2016年,YouTube发表论文(2),将深度神经网络应用推荐系统中,实现了从大规模可选的推荐内容中找到最有可能的推荐结果。
自第一个推荐系统诞生,至今已有二十多年。现在,算法推荐的思路和应用,已经深入到很多互联网应用中。
比如,内容分发平台的个性化阅读(今日头条、抖音等)、搜索引擎的结果排序(谷歌、百度等)、电商的个性化推荐(亚马逊、淘宝等)、音视频网站的内容推荐(如Netflix、YouTube等)、社交网站的(Facebook、微博、豆瓣等),等等。
根据第三方监测机构“易观”发布的《2016中国移动资讯信息分发市场研究专题报告》:2016年,在资讯信息分发市场上,算法推送的内容将超过50%。到今年,这个比重想必更大。

如今,人们探讨算法分发的价值,最常提到的是提高了信息分发的效率,它表现在:解放了部分人力,同时突破了人力对信息分发造成的限制,实现长尾内容的有效分发,从而更高效地完成人和信息的匹配。
然而,还有一层意义较少有人触及:通过算法实现的个性化推荐,真正关注和理解个体。每一个个体都是一个意义不同的“终端”,而不是永远将个体置于群体中去总体理解。也即尼葛洛庞帝所言的“在数字化生存的情况下,我就是‘我’,不再是人口统计学中的一个‘子集’。”——这也是“personal”(个性化)中“person”的意涵所在。
人性面前,算法有更多可能
算法为人智能地匹配信息,但它推荐的依据还是在于人。
即便推荐算法发展得更加成熟,人们在和算法的日常相处中,也难免会有一些困惑:有时,希望算法再“聪明”、更理解自己一些;有时,并不想老关注自己感兴趣的内容,也想看看公共热点;还有时,会猜想自己除了这些需求之外,会不会也有其他的潜在兴趣?……
今天,对内容推荐的批评声音中,包括让视野窄化、信息低俗化、人的边缘化等——这些声音从根本上折射出人类永恒关注的问题:信息的宽度和高度,以及人的主体性。面对这些追问,也许转而用一种整体的和发展的视角,更有利于我们去理解问题。
首先,算法推荐是重要的,但它并非全部。人类有多种信息需求场景,不同的信息分发方式和工具在互相配合来满足用户的需求。这些分发方式的具体工具,或许在不同阶段此消彼长,但本质上并没有完全取代对方。
举个简单的例子:假设一个初级电影爱好者想在周末看一部电影,会有几种可能?如果他今天想看库布里克的作品,他可能直接打开搜索框,搜索“库布里克”导演,看看他导演的作品还有哪些自己没看过;如果他自己没有特定的想法,便可能打开个性化推荐的APP,在熟悉自己喜好的信息流中,刷一刷看有没有感兴趣的电影;当然,如果他运气好,微信加了一个电影发烧友,也可以直接请对方推荐几部。
从这个例子中,可以看到:搜索引擎满足了用户有明确目的时的主动查找需求;而推荐系统能够在用户没有明确目的的时候,帮助他们发现感兴趣的新内容——从这个意义上看,“推荐”和“搜索”实际上是满足人们不同需求的两个互补的工具。
当个性化推荐应用发展迅速的时候,人们可能会不由自主地假设它占据自己的全部信息场景;然而,在现实情况里,一个人在日常生活中接触信息的渠道,远比我们想象得要更加丰富——2016年Seth Flaxman等学者进行的一项实验,也证明了这个结论(3)。
该研究请5万名参与者,自主报告自己最近获取信息的新闻媒体来源,同时通过电子手段直接监测和记录他们的实际新闻消费行为,包括网页浏览历史等。两项数据的对比后,研究最终发现人们实际的媒体消费比他们所想象的更具有多样性。
再者,从根本上来说,算法是运用智能来解决信息分发问题的思路,而非一个绝对的和定型的操作手段,它本身也在不断发展。算法与编辑、社交并不对立,将三者有机结合可以帮助实现更有效的信息匹配。
《内容算法》一书中,作者把算法比喻为“是个筐,什么都能往里装”:算法是基于我们对现实世界的理解进行的抽象和建模,所有我们关心的因素(编辑分发、社交分发)都可以转化为算法推荐的参考因素。
实际应用的推荐系统通常都会使用多种推荐算法,来提高推荐系统的个性化、多样性、健壮性(即鲁棒性)。比如:运用基于内容的推荐算法,解决用户和内容的冷启动问题;在拥有了一定的用户行为数据后,根据业务场景的需要综合使用基于用户的协同过滤(UserCF)、基于物品的协同过滤(ItemCF)、矩阵分解或其他推荐算法进行离线计算和模型训练,并综合考虑用户的社交网络数据、时间相关和地理数据等进行推荐。
与此同时,人工编辑也在关键的时候发挥作用。比如在今日头条平台,由人工审核和机器算法共同对内容进行把关。一个拥有良好推荐机制和规则的平台,能够助力高质量内容的传播,从而促进内容生态的发展。新技术环境中,专业内容生产和编辑团队的价值不仅不会褪色,还会越来越重要。
最后,从人们围绕算法分发的探讨中,可以看到人们面对信息时的两对永恒需求——个人向和公共向、已知的和未知的。人类永远希望二者可以达到动态的平衡,而这个平衡点又往往因人而异。这给算法的发展和完善提供了动力,也带来了难题。
对于个体来说,一个趋于理想态的信息生态,可能需要具备社会性、群体性、个体性,兼顾信息的高度和宽度——有些问题,算法可以解决,也正在尝试解决;但有些问题,可能人类自己也无法很好地解题,最终还是要不断回归到人性本身。信息分发技术发展和完善的背后动力,还是在于人,在于人对信息分发理想模式的永恒追寻。在这过程中,人始终具有其独特的价值和能动性,坚守“技术为人”。
结尾
算法分发是未来之物,它是信息过载时代智能分发的产物;算法分发或也终将成为过去之物,因为下一代技术的发展永远可以突破当代人的想象,就像宋朝人无法想象移动互联网。但无论如何,人类追寻信息的脚步是不会停止的,这种追寻就是信息分发长河奔流的动力。
追问了推荐算法的“前世”与“今生”,那么在技术发展的未来,算法的“来世”会是如何?



